
Introduction
Over the last year, generative AI tools have made the jump from research prototype to commercial product. Generative AI models like OpenAI’s ChatGPT and Google’s Gemini can now generate realistic text and images that are often indistinguishable from human-authored content, with generative AI for audio and video not far behind. Given these advances, it’s no longer surprising to see AI-generated images of public figures go viral or AI-generated reviews and comments on digital platforms. As such, generative AI models are raising concerns about the credibility of digital content and the ease of producing harmful content going forward.
Against the backdrop of such technological advances, civil society and policymakers have taken increasing interest in ways to distinguish AI-generated content from human-authored content. The EU AI Act contains provisions that require users of AI systems in certain contexts to disclose and label their AI-generated content, as well as provisions that require people to be informed when interacting with AI systems. The National Defense Authorization Act (NDAA) for Fiscal Year 2024 has provisions for a prize competition “to evaluate technology…for the detection and watermarking of generative artificial intelligence.” It also has provisions for the Department of Defense to study and pilot an implementation of “industry open technical standards” for embedding content provenance information in the metadata of publicly released official audio/video. Last fall, Senator Ricketts introduced a bill requiring all AI models to watermark their outputs. Perhaps most prominently, the White House announced last summer that it had secured voluntary commitments from major AI companies to develop “robust technical mechanisms to ensure that users know when content is AI generated,” such as watermarking or content provenance for audio/visual media. The subsequent White House Executive Order on AI directs the Department of Commerce to identify and further develop standards for labeling AI-generated content, and at the UK AI Safety Summit, seven leading AI companies announced company policies on “identifiers of AI-generated material.”
The motivations for such interest are diverse, including limiting the proliferation of spam, targeted deception, and scams; suppressing non-consensual pornography and targeted harassment; limiting misinformation/disinformation; safeguarding the future of education, admissions, and hiring; confirming authenticity of content for legal proceedings and public comment; maintaining public trust in media; and even maintaining the ability to improve future generative AI models by ensuring that they are not trained on AI-generated content since this can hurt their performance.1 To be sure, the usefulness of AI detection tools will vary with the domain. In particular, some scholars have argued that for concerns like disinformation or spam, content distribution might be more of a bottleneck than content generation; after all, tools to generate synthetic audio/visual media (like Photoshop or Instagram filters) have been around for a while. Nevertheless, generative AI does significantly reduce barriers to generating large volumes of synthetic media across many domains. Thus, AI detection tools can serve as one part of a larger toolbox to help platforms track and limit the distribution of spurious AI-generated content and individuals assess the credibility of digital content.
There are several ideas for how to tell whether a given piece of content—be it text, image, audio, or video—originates from a machine or a human. This report explores what makes for a good AI detection tool, how the oft-touted approach of “watermarking” fares on various technical and policy-relevant criteria, governance of watermarking protocols, what policy objectives need to be met to promote watermark-based AI detection, and how watermarking stacks up against other suggested approaches like content provenance.
How should we judge an AI detection tool?
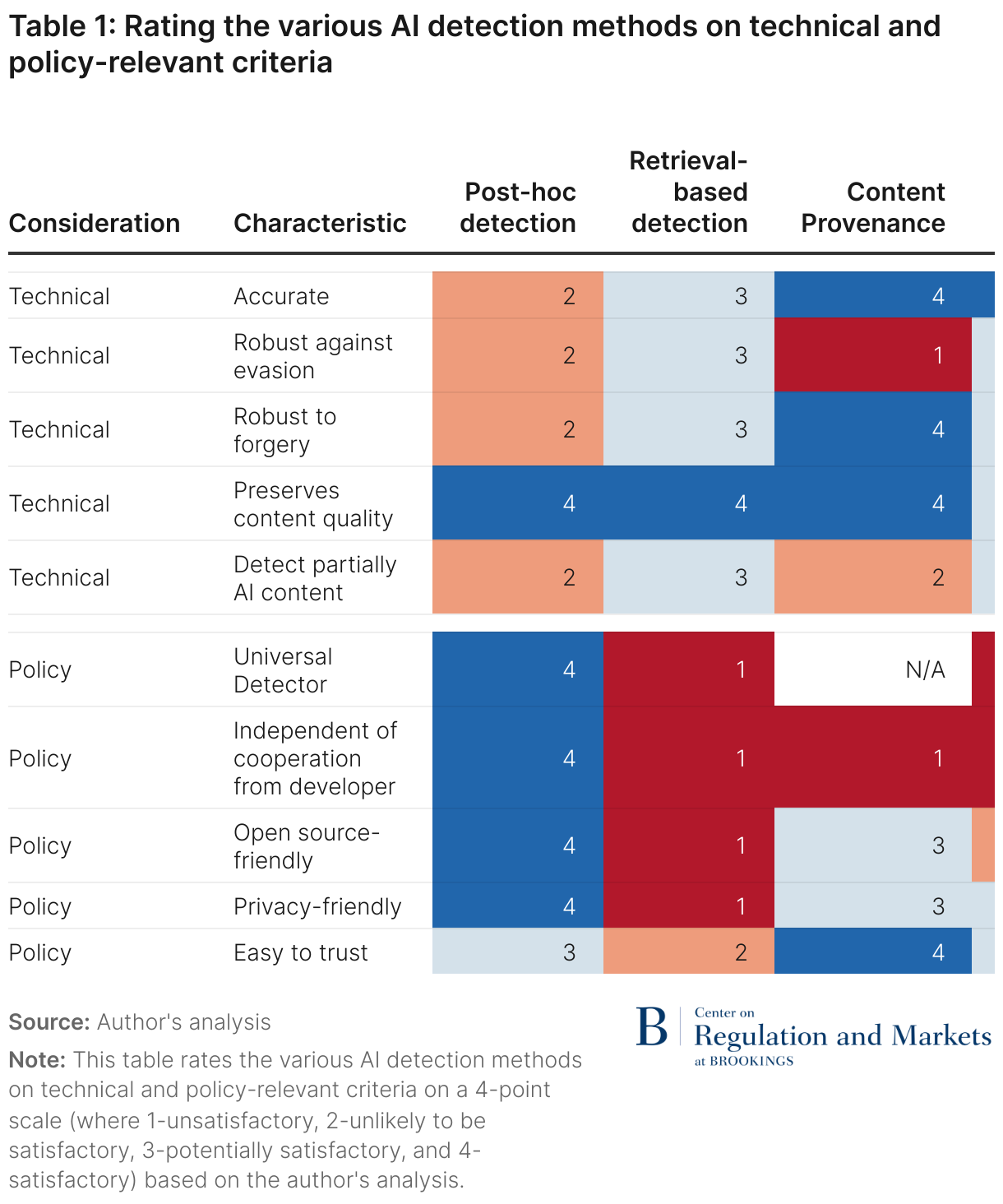
There are several approaches that have been proposed for detecting AI-generated content. The four most prominent approaches are watermarking (in its various forms), which is the embedding of an identifiable pattern in a piece of content to track its origin; content provenance, which securely embeds and maintains information about the origin of the content in its metadata; retrieval-based detectors, where all AI-generated content is stored in a database that can be queried to check the origin of content; and post-hoc detectors, which rely on machine learning models to identify subtle but systematic patterns in AI-generated content that distinguish it from human-authored content. The viability of such tools as practical solutions to detect AI-generated content hinges on several key technical and policy-relevant considerations, which are described below and summarized in Table 1.
Technical criteria
- Accuracy: An AI detection tool must accurately distinguish AI-generated content from human-authored content, ensuring low rates of false positives and false negatives. In other words, the tool should not only correctly identify AI-generated content as such but also ensure that genuine human-authored content isn’t erroneously mislabeled as AI-generated. Additionally, tools that go beyond binary responses (“yes” or “no” that the content was AI-generated) to provide a probability that a piece of content is AI-generated can aid contextual decision-making. The exact tolerance for errors will depend on the context, but even a 1% false positive rate is unlikely to be good enough for many practical use cases like spam detection or education.
- Robustness against evasion: AI detection tools will often be used in situations where a motivated actor is deliberately trying to pass off AI-generated content as human-authored. Thus, an AI detection tool should be robust against deliberate attempts to avoid detection. Common tactics to fool detectors of AI-generated text include paraphrasing text or translating to a different language and translating back to the desired language, in the hope of shaking off any trace that the original content was AI-generated. For image-based detectors, common evasion tactics involve cropping images, subtle pixel alterations, or overlay filters. A good AI detection tool should not be easily fooled by such tactics.
- Robustness to forgery: AI detection tools may potentially also have to handle the opposite problem where a motivated actor either attempts to pass off human-authored content as AI-generated or to pass off one AI model’s creations as that of another. It’s unclear how important this criterion is since evasion is likely a more typical attack than forgery. This reverse problem of the “liar’s dividend” (where one attempts to pass off human-authored content as AI-generated) has garnered some attention, though it’s not obvious that AI detection tools address such concerns in practice. Robustness to forgery may yet be important in the future if we care not only about whether a piece of content was AI-generated but which AI model generated that content (e.g., for liability reasons), though this is speculative.
- Preservation of content quality: Some AI detection tools may rely on introducing detectable quirks in AI-generated content which can potentially degrade its quality; model developers, downstream developers, or consumers who seek top-quality models may balk at having to build or use intentionally degraded products.
- Detection of partially AI-generated content: Often, a piece of content might be neither fully AI-generated nor fully human-authored, especially if there is back-and-forth collaboration with an AI model (e.g., jointly brainstorming with a language model on an essay, or various visual filters on Instagram). In these cases, can the AI detection tool pinpoint how much is AI-generated and how much is human-authored?
A note on detecting AI-generated text vs. images, audio, video: In many ways, detecting AI-generated audio/visual content is easier than detecting AI-generated text. With text, what you read is all there is, so if the writing is coherent and mostly grammatical, there might not be an easy way to tell if it originated from a human or machine. However, realistic AI-generated audio/visual content can easily hide (or be made to hide) small imperfections and imperceptible artifacts that can be picked up by a machine. Thus, current AI detection tools for text are likely to perform worse than those for audio/visual content.
Policy-relevant criteria
- Is the method a ‘universal’ detector? Is the AI detection tool universal, i.e., can it identify content generated by any AI, or just those generated by the specific corresponding AI model? This has important governance implications: Without a standardized way to track or access all AI detection tools corresponding to AI models, checking if content is AI-generated becomes a costly, inefficient, and ad hoc process of trying all available AI detection tools one at a time and still not being sure if some given content is AI-generated, as we may simply not have tried the correct detection tool.
- Does the method require cooperation from the developer? A non-universal AI detection tool that requires the model developer’s cooperation to build, operate, or maintain, involves the following governance considerations: (1) the cost to the model developer; (2) intellectual property considerations if publicly releasing the detection tool reveals proprietary information about the AI model; (3) arrangements to ensure continued availability of a detection tool in case the model developer goes defunct; and (4) international coordination to ensure that foreign model developers are participating in building AI detection tools for their models and in making these tools accessible.
- Is the method compatible with open-source release of models? When an AI model is released open source, the model can be downloaded by anyone and run on their personal machine; the original model developer no longer has any visibility or control over what the model generates. AI detection tools that are undermined by the release of the corresponding AI model (e.g., the tool becomes easy to evade), and tools that require active participation from the model developer are likely to be incompatible with open-source release of models.
- Does the technique have substantial implications for privacy? Does building or using an AI detection tool have any significant implications for privacy of users of the AI models or third parties?
- Is the detection tool easy to trust? AI detection tools that empower non-technical users to authenticate content and do not require trusting third parties are likely to be viewed favorably.
Unfortunately, there is no technically sound AI detection tool that simultaneously also fares well on all policy considerations (see Table 1); the prospect of developing a practical AI detection tool that can always reliably identify AI-generated content is looking increasingly slim. Indeed, some of the core skepticism around AI detection tools comes from a view that motivated actors can easily bypass any measures taken to ensure that AI-generated content can subsequently be detected. Nevertheless, it takes some technical sophistication to circumvent AI detection tools and enabling the detection of a major chunk of AI-generated content can still be worthwhile. With further technical advances and policymaker attention, there are grounds for optimism that a significant fraction of AI-generated content can be reliably detectable. Let’s take a closer look at these AI detection tools, focusing primarily on the most prominent and promising approach: watermarking.
Watermarking, in theory
Watermarking is the process of embedding an identifying pattern in a piece of media in order to track its origin. Watermarking has been extensively used throughout history for physical photos or documents, and the advent of digital media prompted the development of techniques for digital watermarking of images, audio, video, and digital text. Indeed, digital watermarking is not one technique but an umbrella term encompassing several different approaches to embedding patterns in digital media. The most promising watermarking techniques available today are “statistical watermarking” and machine learning-based watermarking, although future research may uncover other promising approaches as well. It’s important to note that sophisticated watermarks embed subtle patterns imperceptible to the human eye (akin to an idiosyncratic writing or art style), and so they typically can only be detected by a computer (with the potential for errors). It’s also worth clarifying here that we are discussing the watermarking of AI-generated content, not the watermarking of AI models (to combat model theft) or the watermarking of data used to train AI models (to combat unauthorized use of data).
Visible and invisible watermarks
The simplest digital watermarks add a visible label to an image, a unique sound to an audio clip, or a citation in text. A simple example is the five colored squares at the bottom of a DALL-E generated image. Even the common ChatGPT-generated preamble “as a language model trained by OpenAI” can be considered a crude watermark. Of course, such watermarks are easy to remove and easy to forge, making this an extremely unreliable way to determine origin.
More involved traditional approaches hide or obscure the watermark to make it harder to remove or forge. Since images, audio, and video contain a fair amount of detail, there is a lot of room to hide subtle, imperceptible patterns, and so these media are generally easier to watermark. While it’s much harder to hide a pattern in text, it is possible to use sophisticated approaches from the field of steganography, the technique of hiding messages in simple text through secret patterns in word choice or order. Now, even though these techniques raise the barrier to forging watermarks, it’s still fairly easy to corrupt or remove these watermarks with minor edits, which is usually the more pressing concern. For audio-visual content, adding blurs or noise can degrade watermarks; for text, changing a word can dramatically garble a steganographic message. As such, the traditional approaches to watermarking may be too easily corrupted to serve as a reliable AI-detection method.
Researchers have recently begun exploring machine learning-based approaches to watermarking images in particular. One approach studied by researchers from Meta uses a machine learning model to embed a hidden watermark based on a ‘key’ that can later be detected by another machine learning model. The approach performs well on unmodified images in their experiments, with the accuracy slowly declining the more images are modified. Additionally, it takes direct access to the AI model and some sophistication to remove or forge the watermarks. Google also recently announced SynthID, an experimental tool for watermarking and identifying images generated by the company’s AI models that uses one machine learning model to embed an imperceptible watermark and another model to detect the watermark. However, like a lot of deep learning-based methods, these approaches are not entirely resistant to attacks: Researchers from Duke University found it possible to make small, imperceptible modifications to pixels to fool machine learning-based watermark detectors. As for watermarking audio/visual content, there are not really any well-explored approaches. Google’s SynthID can supposedly be used to watermark audio, though the tool is still being tested and details about how well it works have not been disclosed. Nevertheless, it takes a moderate level of technical sophistication to fool these watermark detectors, making it unlikely to be evaded en masse. Thus, further technical advances and policy interventions could still enable machine learning-based watermarking of most audio/visual content, though one should remain cognizant of the limitations.
Statistical watermarks
Perhaps the watermarking technique drawing the most research interest is “statistical watermarking,” where instead of embedding a clearly defined pattern in text or audio/visual content, an algorithm embeds a statistically unusual arrangement of words/pixels/sounds. Statistical watermarking for generative AI is a fast-moving area of research, and there is no settled best practice for implementing this scheme. However, at a high level, a statistical watermarking scheme for a generative AI model consists of two sub-protocols: generation and detection.
- Generation: Here, a hidden statistical pattern is embedded in the AI-generated content when it is being generated. This is possible because generative models typically have some freedom in how they respond to a user’s prompt, so they rely on the randomness of “virtual dice” to pick their response. The generation protocol “loads the dice” according to a cryptographic scheme known to the model developer; then when the AI model generates an output by rolling the loaded dice, it is nudged to avoid certain outputs and favor other outputs and thus induces a hidden statistical pattern (i.e., a watermark) in the generated content.
- Detection: An AI model’s detection protocol can be used to check whether a given piece of content was generated by that particular AI model. This detection protocol analyzes the content for patterns that should exist if it was in fact generated using the generation protocol (and so must know details of this generation protocol). Specifically, the detection protocol can compute the probability of producing the observed patterns in the content without the generation protocol, purely by chance. The lower the chance, the more confident we can typically be that the content was generated by the corresponding AI model.
Put simply, the idea behind statistical watermarking is to put a thumb on the scale of randomness during generation so it leaves a fingerprint that can be detected later. Researchers have advanced a few proposals for watermarking text and images, although more foundational research is needed on statistical watermarking of audio and video.
Statistical watermarking for text: Since language models generate text one word at a time using randomness, one approach (studied independently by researchers at the University of Maryland and OpenAI) is to make the language model randomly favor certain words and avoid other words based on what came before.2 The model developer knows how this randomness was introduced and thus what words were favored; a detection protocol simply checks if favored words appear unusually frequently in a piece of text. A downside of artificially promoting or avoiding certain words is that there could be some degradation in quality (though the approach by OpenAI does not degrade quality in principle). A proposal by Stanford researchers takes a different approach: Instead of rolling loaded dice to artificially favor certain outputs over others during generation, they pre-determine the “dice rolls” that the language models must use to generate content and store this as a key. The detection protocol then checks whether a given text correlates to an unusual degree with the predetermined dice rolls (accounting for potential edits) to identify whether the text is watermarked. While these are some of the more prominent approaches, there has been a recent explosion of research interest in this area.
Statistical watermarking for images: Statistical watermarking of images (or audio or video for that matter) is a much more nascent research topic. Prominent generative AI models like Stable Diffusion and Midjourney work by starting with a random image (which looks like static on a TV), and progressively editing it into an intelligible picture based on a prompt. Researchers at the University of Maryland developed “tree-ring watermarks,” where the generation protocol embeds a hidden pattern in the initial random image based on a key known to the model developer and in doing so favors particular image outputs. During the detection protocol, this scheme reverses the edit process to produce the original random image, which can then be checked for the watermark. Unlike other watermarks for images, this approach does not introduce any artifacts in the image so there is no degradation in quality. Additionally, common image modifications—cropping, blurring, rotating—do not easily degrade the watermark, and it is hard for an attacker to guess how to manipulate the image to erase the watermark without access to the AI model. On the other hand, detecting the watermark requires access to the image AI model, which is challenging for closed-source models. Perhaps owing to the popularity of other approaches, statistical watermarking for audio-visual content has been relatively underexplored.
Statistical watermarks are one of the more accurate watermarking schemes that are also relatively resistant to erasure or forgery (potentially even more so if certain details are kept secret). It also appears possible to embed a statistical watermark without significantly degrading content quality and to detect partially AI-generated content. Additionally, while there are a number of plausible approaches for watermarking images, statistical watermarks are the only viable watermarking technique for text today. From a technical perspective, statistical watermarking, particularly for text, shows promise.
At the same time, statistical watermarking has important limitations. First, embedding a statistical pattern in AI-generated content isn’t always easy or even possible. Statistical watermarking is constrained by how much “room” there is for randomness in the output of an AI model; there are typically more ways to generate audio/visual content in response to a prompt as compared to text, so it’s easier to statistically watermark audio/visual content compared to text. For similar reasons, some kinds of text are easier to watermark than others: There are many ways to write a children’s story, fewer ways to write correct code or solutions to a math homework, and only one correct way to regurgitate a copy of the Declaration of Independence. As such, it’s straightforward to watermark the children’s story, harder to watermark code or math homework, and impossible to watermark the generation of historical documents. The reduced room for randomness can be counteracted to some extent by acquiring a large enough volume of content so even a weak statistical pattern can be detected, but this may not be possible depending on the application context. Second, this technique requires AI models to incorporate randomness in their generation, even though it is possible to generate content deterministically. Model developers may balk at this if their desired application or future AI models are unsuited to such randomness. Third, we need more research on the robustness of statistical watermarks. There is already some early research showing a proof-of-concept attack to erase statistical watermarks for text. It would be helpful to have a comprehensive and standardized (and frequently updated) battery of attacks for benchmarking watermarking schemes; this will help evaluate whether statistical watermarks are practically useful. It will also be critical that watermarks do not meaningfully degrade the quality of AI-generated content.
Watermarking: Practice and policy
The White House announced this past summer that leading AI companies had voluntarily committed to “developing robust technical mechanisms to ensure that users know when content is AI generated, such as a watermarking system,” although the commitment appears limited to audio/visual content and excludes language models. Leading AI companies further reiterated their commitment to developing ‘identifiers of AI-generated material’ at the UK AI Safety Summit, and the White House Executive Order on AI directs the Department of Commerce to identify and develop watermarking standards.
As discussed previously, watermarking refers to a broad array of techniques, and these commitments do not go into detail on the kind of watermarking systems that will be developed. Yet, only sophisticated watermarking techniques which preserve content quality and are hard to remove or forge could be a practically viable way to detect AI-generated content.
Watermarking in practice
In addition to the technical questions about the viability of watermarking, policymakers should be aware of how sophisticated watermarking techniques fare on the policy-relevant criteria discussed previously, as this will inform policy objectives as well as the merits of further encouraging or even mandating watermarking of AI-generated content.
- Watermarking is not a “universal” detection solution, i.e., watermark detectors must check separately for every existing watermark. The watermark implemented by one model developer only lets them later verify whether a piece of content was generated by their own model (e.g., Google’s SynthID can only detect watermarks embedded by Google’s image AI models). To check if a piece of content carries any AI model’s watermark, one essentially needs to try the detection protocol of every AI model until one gets a hit, and in the absence of a hit, the worry that one simply didn’t check against the correct AI model’s detection protocol would remain.
- Watermarking requires the AI model developer’s cooperation. Embedding watermarks will require the model developer’s cooperation. Additionally, for current watermarking schemes, ensuring that the watermark isn’t easily removed or forged may require the model developer to keep key details or components of the watermark generation scheme private. Measures also need to be in place to ensure that an AI model’s watermark detection service continues to exist even if a model developer discontinues a particular AI model or goes out of business, since content generated by the model will continue to circulate in the wild. Lastly, since digital content can easily flow across borders, policymakers will need to secure the cooperation of foreign model developers to ensure that their model outputs are watermarked too.
- Open-source release of AI models poses significant challenges for watermarking. This stems from the fact that watermarking is not universal and requires the model developer’s cooperation. Even if the open-sourced AI model embeds a watermark in its content by default, it can be as straightforward as removing a few lines of code to disable the watermark generation after downloading the model onto a personal machine. Furthermore, there is no clear mechanism by which open-source developers can ensure—if technically necessary—that key details of the watermarking scheme are kept secret from users yet accessible for watermark detectors.
- Watermarking presents important privacy considerations. There are two main privacy considerations: (1) Does the watermark also include information about the user who generated the content? AI companies’ watermarking commitments announced by the White House say that AI companies “need not include any identifying user information” in their watermarks, but the possibility has not been ruled out. While this could enable tracing the origin of content not just to the model but also to the user (e.g., for liability reasons), this would also infringe on the privacy of users particularly if they are unaware of this possibility; and (2) if watermark detection is operated by some third-party, how should this entity handle the data submitted to it for watermark detection? If anyone can submit any content to a watermark detection service, there are substantial privacy issues with storing such requests (e.g., for training future AI models).
- Watermark detection may require trusting the entity providing the detection service. If watermark detection is operated by the model developer or some third-party (e.g., so that the watermark is hard to remove or forge), it won’t be possible to independently verify the presence of the watermark. Ensuring trust in a watermark detection service is warranted and maintained may require policy intervention as well as international coordination with foreign model developers and watermark detection services. Alternatively, if it is possible to publicly release details of the watermark detection scheme without compromising the watermark’s robustness to removal and forgery, individuals could directly verify the presence of the watermark without having to trust another entity. Additionally, while we can standardize the way watermarking is implemented, each AI model should come with its own distinct watermark for two reasons: (1) so we can trace the content to the model that generated it, and (2) so that details of the watermarking scheme don’t have to be kept private by a potentially large number of model developers and compromising one watermarking scheme doesn’t also compromise all others.
Governance of watermarking protocols
The governance arrangement that makes sense for watermarking of generative AI models depends both on technical progress as well as the degree of commitment toward ensuring the traceability of AI-generated content and robustness to removal and forgery. If watermarking is simply a nice-to-have feature, AI model developers could embed watermarks and publicly release the detection scheme so anyone can check for the watermark. However, under current techniques, it can be relatively easy to produce unwatermarked content by reverse engineering the watermark detector or simply through trial-and-error (i.e., “brute force”). On the other hand, ensuring that even sophisticated actors are unable to produce unwatermarked content will likely require impractical levels of technical progress, international coordination, and tighter regulation of open-source AI models.
A realistic middle-ground that policymakers can aim for is to raise the barrier to evading watermarks for all but the most sophisticated actors, so most—but not all—AI-generated content is watermarked. In practice, this means watermarking will primarily be geared towards managing AI-generated content from popular and commercial models, while being of limited use in high-stakes settings requiring quick decision-making like misinformation during elections or disasters (where malicious actors could deliberately use unwatermarked AI models).
A potential approach to pursue such a watermarking regime is to establish a trusted organization with the following two responsibilities:
- Standardize watermarking and maintain a registry of watermarked models and detection services: Watermark detection tools are not universal; each model developer can only be responsible for ensuring their own models generate watermarked outputs. Without intervention, users would have to query each company’s (potentially different) watermark detection service ad hoc to check if a piece of content is watermarked. If AI models continue to proliferate, it would be helpful to have a public registry of watermarked models so users can easily locate and query all “known” AI detection services at once.
- Support watermark detection services: A major question influencing the governance of watermarking protocols is whether the watermark detection scheme can be made public or must be kept private to protect against removal or forgery. Intuitively, publicly disclosing what patterns to look for to find the watermark could make it easy to artificially remove or forge those patterns by reverse-engineering the detector or even by trial-and-error until you succeed. At the same time, generating watermarked content can leak information about the watermark, so the benefits of keeping the watermark detection scheme private may be limited. There is some early research on developing publicly detectable watermarks for language models, but more research is needed to definitively answer this question.If it turns out that publicly releasing a watermark detection scheme has little impact on robustness to evasion or forgery, model developers will require little support beyond the public registry for watermark detection services. However, if details of the watermarking scheme need to be kept private, questions to address will include who is responsible for keeping this information private; who operates the watermark detection service and with what funding; what practices open-source and foreign model developers follow; and how we can trust a private watermark detection service to provide accurate and privacy-friendly services.
One possibility is that model developers stand up the requisite infrastructure to independently operate their own watermark detection service and take any necessary steps to secure details of the watermarking scheme. The proposed organization would provide little ongoing support, though it may need to take custody of the detection protocol if the model developer goes out of business or stops offering the model, since generated content will still be circulating in the wild. Another possibility is for the proposed organization to directly operate watermark detection services. This could require model developers to share sensitive details about the watermarking scheme and potentially the generative AI model3 (depending on the watermarking scheme); model developers would likely need iron-clad guarantees that such information can be kept secure. The feasibility of this arrangement will also depend on the available funding and buy-in from open-source and foreign model developers.
If the organization directly operates watermark detection services, it would likely need to charge fees to cover the costs; the question is whether the fees are paid by users or AI model developers. Practically, charging users per query will help limit “brute-force attacks” to evade the watermark detection by continually making edits to a piece of watermarked content until it fools the detector. If model developers receive some cut of the fees, it can also be a way to incentivize open-source model developers to register with the organization. Alternatively, model developers may have to pay dues to keep a trusted organization operational if free or cheap access to such services is deemed a right. This may also be necessary to ensure that model developers do not pass on the responsibility for operating watermark detection services for sunsetted models to some third-party without providing adequate funding.
One model for a trusted third-party organization that can establish watermarking standards, maintain a database of models implementing watermarks, maintain potentially sensitive information about watermark detection protocols, and engage in international coordination on watermarking is the Internet Corporation for Assigned Names and Numbers (ICANN)—a multi-stakeholder not-for-profit partnership organization responsible for international coordination and maintenance of the internet domain name system (among other things), critical to ensuring the smooth and secure operation of the internet. Policymakers may also wish to require model developers and watermark detection service providers to report certain operational details to a regulator or the public or provide regulatory oversight to ensure that trust in the implementation of the watermark detection service is maintained, especially if the organization possesses sensitive information that can undermine future watermark detectability if compromised.
Governance of open-source models: In order for a watermarking scheme to be fully compatible with open-source model releases, we will need: (1) a watermark that is “baked-in” to the model weights (as opposed to being embedded in an independent step during generation) so it can’t easily be disabled or tampered with by users, and (2) either a trusted entity (of the kind proposed above) that can take secure custody of any private information needed for watermark detection as well as operate the watermark detection service, or a watermark detection scheme that sees limited benefit from being kept private. The machine learning-based image watermarking approaches by Meta and Google discussed earlier “bake in” the watermark, though they require details to be kept private to prevent the watermark from being removed. It’s still an open research question whether it’s possible at all to “bake in” a watermark into a language model so it can’t be easily removed and whether it’s practical to publicly release a watermark detection scheme without making it easy to remove or forge the watermark.
Policy objectives
Given the above considerations, addressing the following list of policy objectives will be important to promote the development of watermarking-based AI detection solutions:
- Promote research and development of technical watermarking standards: Given that watermarking research is still in its infancy, policymakers can support further research into watermarking techniques that overcome current limitations as well as benchmarks for assessing the quality and robustness of a watermarking scheme. It will also be important for industry, academia, and civil society to converge on technical watermarking standards, ideally with an eye toward international coordination. Existing watermarking schemes are not quite ready to be adopted as industry-wide standards, so the feasibility of ensuring AI models produce watermarked content is contingent on further technical progress.Time will be of the essence. The watermarking prize competition in the NDAA is a promising idea, but the end date of December 31, 2025 might be too late to be effective; the landscape of generative AI will likely look significantly different by then. Moreover, content generated by non-watermarked models prior to the competition’s conclusion could become so widespread that tracing their origin may be impossible, even as efforts are made to formalize best practices.
- Identify who needs to watermark: AI models are already quite good at producing realistic text and images and are quickly improving at audio and video generation. Policymakers need to quickly identify the models or deployments for which watermarking is essential. There may well be bonafide cases where watermarks should not be implemented; for example, commercial applications that don’t simply generate content from a model but rely directly on the probabilities that the model assigns to any content, or researchers studying such models for academic purposes.
- Identify the responsibilities of open-source release: Watermarking open-source models is a challenge, as discussed above. It doesn’t make sense to require open-source releases to implement a watermark if malicious actors can easily remove or forge the watermark. One possibility is to not worry about open-source release or private use but focus on public or commercial use of open-source models, or on downstream developers who build on the open-source models as the locus for watermarking responsibility. Even so, malicious actors can ignore such obligations, and it would be hard to trace content back to them since the content lacks the watermark in the first place. If a robust watermarking scheme compatible with open-source models discussed previously is developed, it may then be possible to encourage or require open-source releases to “bake in” the watermark implementation before release and share watermark detection details with some trusted third-party who assumes responsibility for watermark detection. At any rate, tracking and enforcement here will be a challenge, so we should be clear-eyed on what problems such measures can and can’t solve.
- Shape the development of watermark detection services: Policymakers can shape the creation of a trusted entity that maintains registries of watermarking schemes or operates watermark detection services. Such an entity will require some oversight to ensure secure handling of any private watermarking information. International coordination will also play an important role in the success of such an entity.
- Establish continuity plans for watermark detection: If an AI model developer stops offering a particular generative AI model or goes out of business, we would still want to preserve the ability to detect content previously generated by that model that is already circulating in the wild. To this end, it would be important to determine who assumes responsibility for watermark detection if an AI developer dissolves.
- Clarify privacy protections: Policymakers should clarify how watermark detection services should handle any data submitted to them; a privacy-friendly approach would be to prohibit watermark detection services from storing or selling data submitted to them. Policymakers should also clarify what information watermarks should contain, especially whether watermarks can contain information about the user.
While tackling the objectives above can help establish watermarking as a feasible approach to detecting AI-generated content, policymakers should understand the practical limits of watermarking. Watermarking most AI generated content will be helpful in identifying the origin of digital media, but it will not be practical to watermark all AI-generated content.
Other approaches to detecting AI-generated content
While watermarking is perhaps the most prominently discussed AI detection approach, three other technical approaches have also received a fair amount of attention: post-hoc classifiers, retrieval-based approaches, and content provenance. Table 1 summarizes and compares these tools with watermarking on the aforementioned criteria.
Post-hoc detectors
The simplest idea to detect whether content was produced by human or AI is to “fight AI with AI.” The hypothesis is that AI-generated content has systematic (if subtle) differences from human authored content, which can be picked up by a machine learning model. This approach requires no intervention when the AI model generates content, instead focusing only on verifying content after it has been generated (hence, post-hoc). In terms of the policy-relevant criteria, this approach is entirely compatible with the open-source release of models (since it requires no intervention when the model is used to generate content) and does not pose any privacy concerns for AI model users or third-parties.4 Whether a post-hoc detector is universal or requires pro-active cooperation from the AI model developer depends on the details of the implementation.
- Post-hoc detectors for text: A number of the most popular AI detection tools for text like OpenAI’s AI Classifier and GPTZero are post-hoc detectors that are also universal and do not require active cooperation from the model developer. Unfortunately, these detectors do not work well enough. OpenAI recently shut down their AI classifier because of its “low rate of accuracy,” and even more sophisticated but non-universal post-hoc detectors like DetectGPT are not sufficiently accurate and can be easily fooled by simply paraphrasing the text. It is not uncommon for these tools to mistakenly classify short texts, non-English texts, or famous classical texts like the U.S. Constitution as being AI generated. At best, these post-hoc detectors can help make an educated guess in the presence of other contextual information. At worst, they can do more harm than good, for instance by unfairly accusing students of cheating or flagging non-English speakers’ writing as AI-generated spam. An insufficiently accurate AI detection tool is likely to cause significant harm—we need much lower false positive rates than are currently achieved with these models.
- Post-hoc detectors for images, audio, and video: Current post-hoc detectors for images, audio, and video have primarily focused on an important subset of AI-generated audio/visual media: deepfakes or AI-generated likenesses of individuals. Indeed, deepfake detectors by Intel and DuckDuckGoose achieve 96% and 95% accuracy respectively, compared to the lower than 30% accuracy of post-hoc detectors for text generated by GPT-3.5.5 However, whether this level of accuracy is good enough depends on the use-case: for a platform screening millions of pieces of content to automatically flag AI-generated media, a 1-in-20 failure is likely too high.
One might contend that even if post-hoc detectors aren’t very good today, it’s only a matter of time before the technology improves enough to be reliable and practical. Unfortunately, the opposite is far more likely. As AI models improve and produce more realistic writing and audio/visual media, AI-generated content will have an easier time passing as human-authored content. While post-hoc detectors could potentially be used as part of a layered approach in relatively low-stakes scenarios, it is unlikely to be a reliable standalone approach for detecting AI-generated content given the already insufficient accuracy rates.
Retrieval-based detection
Retrieval-based detection is the idea of storing the content generated by a given model in a database maintained by the model developer and subsequently comparing any query against this database to check if it was AI-generated. In the generative AI context, a retrieval-based detector wouldn’t just look for an exact match as simple plagiarism checkers typically do; instead, it would look for matches in the database based on the underlying meaning or content. For retrieval-based detection to work against motivated adversaries, it also needs to be robust to subtle manipulations in AI-generated text (like paraphrasing) and audio/visual content (like crops, rotations, flips). In the language context, this technique was found to be more accurate than post-hoc detection, though it may still not be reliable enough. While there hasn’t been much research on retrieval-based detection for AI-generated images, similar ideas have been explored for tracking non-AI generated images in online terrorism, non-consensual intimate imagery, and child sexual abuse material (CSAM).
The most central policy-relevant consideration for retrieval-based detection is user privacy, since this method requires the AI model developer to store all generated content indefinitely. Even though tools like ChatGPT do store user generated content to improve models, users currently have the option to opt out of this feature. An important difference with retrieval-based methods for terrorism or CSAM is that the latter are limited in the scope of content they store, and critically, only store “hashes” or garbled versions of the content that cannot be reverse-engineered to recreate the stored information. International coordination on such an expansive centralized database will also be challenging. Furthermore, storing user data in this manner may run afoul of data privacy laws in other jurisdictions (e.g., the EU’s General Data Protection Regulation (GDPR) requires data collectors to minimize the amount of data they collect and store to “what is necessary in relation to the purposes for which they are processed”)—which may mean content generated by users from these jurisdictions may not legally be stored. Ultimately, retrieval-based detection imposes costs on the model developer and requires their active involvement; is not a universal detection technique; is not compatible with the open-source release of models; and perhaps most crucially, is not friendly to user privacy. For all these reasons, retrieval-based detection is unlikely to be a practical solution to detecting AI-generated content.
Content provenance
Another approach to detecting AI-generated content is to store information about the origin (or provenance) of a piece of content in the metadata. Perhaps the most prominent such initiative is the Coalition for Content Provenance and Authenticity (C2PA), a coalition of technology and media companies including Microsoft and Adobe. C2PA has proposed an open technical standard for maintaining a record of the origin and modification history of audio/visual media in the metadata. This specification defines a common format and structure for metadata that can be attached to different types of files, indicating the location, time, editing, authors, publishers of the content, and potentially even watermark information (the standard also allows for anonymous content). The metadata is secured against tampering using cryptographic methods, so any manipulation of the file can be reliably detected. Any software or platform using the standard can allow users to directly inspect the provenance information of any content to learn where the content originated and how it has been modified. The content provenance information can be tracked in a coordinated way across platforms/software that use this standard. The approach is specifically focused on fighting online misinformation and disinformation, so AI-generated content is only one of the considerations in the design of the standard.
Storing content provenance information in metadata may be helpful in some applications pertaining to disinformation (e.g., when platforms wish to flag the authentic version of an image or clip that has been doctored to go viral). Indeed, the FY24 NDAA has provisions for a pilot program to explore whether it makes sense for the Department of Defense to implement “industry open technical standards for digital content provenance” (likely to be C2PA’s standards) for publicly released official audio/video. While content provenance will help when good-faith cooperative actors maintain the provenance information as it circulates to affirm its authenticity, it is unlikely to be a reliable way to detect AI-generated content in contexts where individuals are uninterested in maintaining or actively seeking to undermine provenance information, like spam-detection or education. It’s easy to simply copy text, screenshot images, or re-record audio/video content to create a new copy of the content without the original provenance information, so the standard is easy enough to evade for even relatively unsophisticated malicious actors. Furthermore, if the standard doesn’t obtain broad buy-in, the vast majority of content will not have valid provenance information in the metadata, and we have not really solved the problem of identifying AI-generated content.
Conclusion
This report has provided an overview of how watermarking works, the policy objectives to promote the use of watermarking-based AI detection, and a brief overview of the other approaches to detecting AI-generated content. Sophisticated watermarking techniques show promise as a way to identify AI-generated content, and could play a role in helping platforms, educators, juries, etc., identify AI-generated content. At the same time, they are not going to be foolproof; a motivated individual can evade AI detection tools or use one of the many open-source models available today. Nevertheless, circumventing AI detection tools will require some technical sophistication, and more technical research into watermarking schemes may help overcome some of the technical and policy-relevant limitations today. A reasonable goal will be to raise the barrier to generating unwatermarked content and ensure that a significant fraction of AI-generated content is watermarked, while recognizing that detecting all AI-generated content will be infeasible. As such, AI detection tools should be treated as one part of a multi-layered, context-specific approach.
Author

-
Acknowledgements and disclosures
The author would like to thank Di Cooke, Jonas Geiping, Tom Goldstein, John Kirchenbauer, Rohith Kuditipudi, Matt O’Shaughnessy, Hadrien Pouget, and John Thickstun for helpful discussions and comments.
The Brookings Institution is financed through the support of a diverse array of foundations, corporations, governments, individuals, as well as an endowment. A list of donors can be found in our annual reports published online here. The findings, interpretations, and conclusions in this report are solely those of its author(s) and are not influenced by any donation.
-
Footnotes
- Currently, cutting-edge language models are trained on vast quantities of data scraped from the internet. Training generative AI models on AI-generated data can lead to deterioration in performance, so as things stand today, AI companies have some incentive to ensure that they do not train on data generated by their own models.
- Technically, language models generate text one “token” or sub-word at a time, but this distinction is not important here.
- For example, the statistical watermark detection scheme for images proposed by researchers at the University of Maryland requires access to the model itself.
- There may still be privacy considerations for the data used to build the post-hoc detector.
- Such accuracy figures cannot be interpreted or compared at face value. As a simple example, if 1% of the email one receives is spam, a spam filter that classifies all emails as not spam will have a 99% accuracy while being useless. Similarly, the false positive rate of a deepfake detector is needed to contextualize the accuracy rate.
The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).


