Social media is here to stay. It is in our lives and our phones, in our news and our politics, and in the manner in which key events are transmitted and interpreted by the public. The tragic murder of George Floyd, for example, was visible for the world to see in large part because the cellphone video permeated social media. Awareness of the protests and the injustices that continue to spark demonstrations largely transpires online. The immediate proliferation of information sharing and receiving has fundamentally changed in a short period, hindering our ability to understand its significance. For example, the first public account of the October 1, 2017 shooting in Las Vegas, the deadliest mass shooting in the United States, came from a tweet about 10 minutes after the first shots began and while shots were still being fired.
As a new tool for social science research, social media has many advantages: a large number of observations in real time and the ability to track public emotions and sentiments before and after key events—thus to isolate changes caused by the events, as well as to assess how they vary across a wide range of locations and topics of discussion. Social media data has been used to assess the social costs of terrorist events and crime, of COVID-19 lockdowns and responses to the lockdowns from public officials, and (by us) of mass shootings in Las Vegas, El Paso, and other cities. There are downsides, of course. It is more difficult to identify the socioeconomic and demographic traits associated with the messages—and while locations can be roughly identified, they are often imprecise and precise locations have few observations. There are also fake messengers spreading false information, a problem that we discuss in detail here.
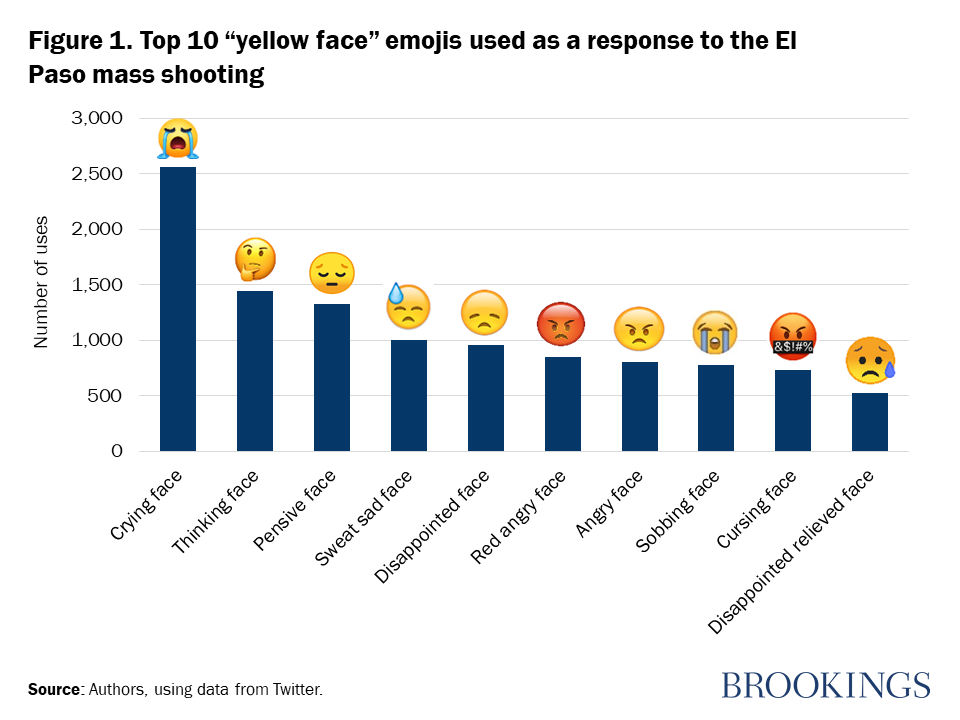
We examined millions of Twitter posts for events, such as mass shootings, that result in a large, international online response. A single tweet contains more than 150 data variables including the time the tweet was posted, the tweet text, the Twitter handle, locations, and more. The hashtags and emojis can also be extracted from the “full text” of the tweets. The hashtags and emojis can also be extracted from the “full text” of the tweets. For the emojis, we mainly focus on the “yellow face” emojis, which can be sorted into different emotion categories: happiness, surprise, sadness, disgust, fear, anger, and neutral (Figure 1). These categories are based on a psychology theory developed by Paul Ekman and Wallace V. Fesen that correlates facial expressions to six primary emotions that are expressed. The other emojis can be sorted into bundles that may pertain to a specific topic, like a mask or a syringe that is associated with medical-related tweets.
Misinformation on social media
Extracting and analyzing the progression of hashtags is also an effective means to uncover the sentiment that users experience. One of us (Mary) does this in a recent paper “How Misinformation Spreads through Twitter” using a Twitter collection curated by UNLV Libraries. Figures 2 and 3 below show the different usages of hashtags that circulated false claims about the “1 October” (Las Vegas) shooting versus those who tried to fact-check those claims.

Source: Author, using Twitter collection curated by UNLV Libraries

Source: Author, using Twitter collection curated by UNLV Libraries
Our own use of the data, though, has also made us increasingly aware of how the data can be misused, and the varying degree of risks that it brings. Because the analysis is so technical as a result of the data structure and quantity, it is all too easy to make mistakes while processing or formatting the data, therefore making it possible to inadvertently manipulate the information. Other issues like the presence of bots, trolls, and cyborgs are a challenge, as they have a heavy online presence and can be used to disseminate content that can include false claims. The followers of many public figures are bots, for example, 61 percent of President Trump’s followers were found to be bots, spam, propaganda, or inactive accounts.
According to the Pew Research Center, as of 2019, 72 percent of Americans have at least one social media account and about two-thirds of Americans at least occasionally get their news from social media platforms; social media usage has only skyrocketed since the COVID-19 pandemic.
While the term “fake news” is often thrown around as an accusation for information that typically contradicts a person’s beliefs, misinformation and disinformation are more serious issues. These terms can be broadly encapsulated by the term “information pollution.” The 2016 presidential election highlighted the vast extent of information pollution that took place, as false stories generated more engagement than factually reliable news. A framework developed by the Council of Europe called Information Disorder outlines the different phases, elements, and players contributing to this phenomenon. Information pollution can be separated into the following categories: misinformation, disinformation, malinformation. Some misinformation is benign, some is much less so. The three categories differ primarily in their intent to harm and level of inaccuracy, but the extent of information that can propagate and its potential to impose harm are all equally severe. These potential harms are intensified since users have the ability to hide or fabricate their identity while creating content that can reach millions of people.
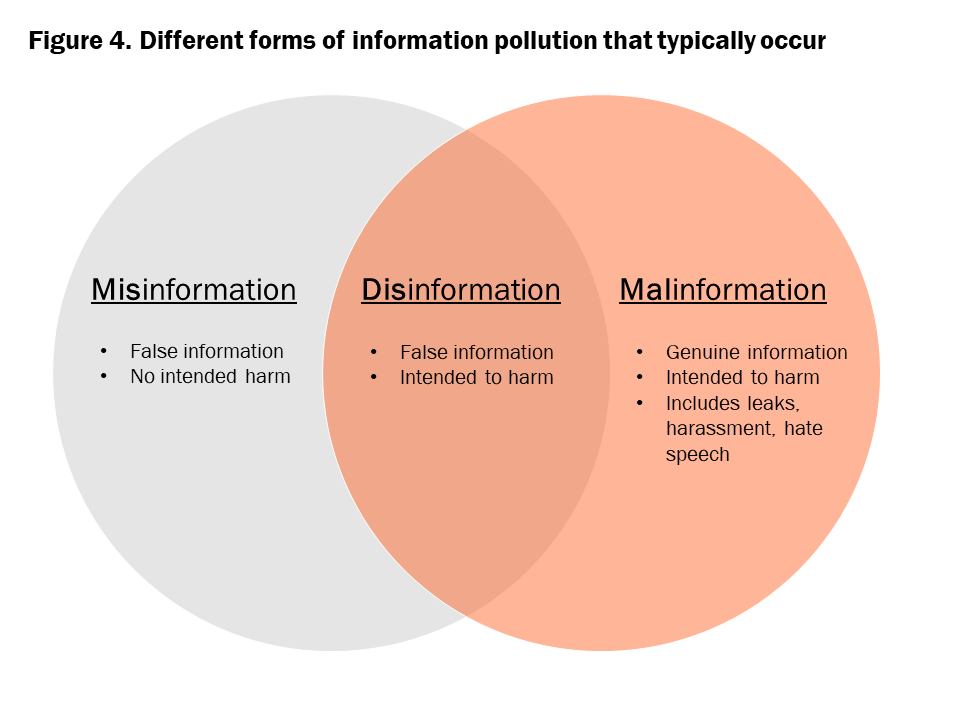
Source: Author, modified from the Council of Europe’s Information Disorder framework.
The vast combination of possible misinformation and the actors that spread and interpret the message can result in a never-ending cycle of information pollution. Once a false message is out, it is easy for it to diffuse and get picked up in news coverage and publications that then get referenced back in social media posts. Misinformation has the greatest chance of becoming widespread when it contains content that exploits feelings of superiority, anger, or fear against another group.
As seen in the case study of tweets pertaining to the 1 October shooting, popular claims included that the Islamic State was responsible for the shooting, that the shooter was part of antifa, and that the shooter was an Islamic convert. The number of identified false claims recorded was typically much higher than the number of attempted corrections, and the newly generated fact-checking tweets decreased much more quickly than those perpetuating false claims. The majority of tweets with false information were made by people living in or having a strong connection to the United States.
We provide much greater detail on this problem in the paper, as well as suggestions for ways in which both public regulation and increased awareness and education by individual users can help mitigate the risks. The problem is that action taken to regulate mis- and disinformation often results in declining transparency of information and in the confinement of the media—while the reverse should occur. Transparency should of course be encouraged. Yet equally important, users already have access to fact-checking and user-checking tools like Botometer or Hoaxy that can be utilized to see whether a user or content is manufactured, even though they often do not know that.
Government and social media companies, meanwhile, need to establish greater cooperation. Yet instead we see retaliation from the executive branch that attempts to strip away immunity for websites to create and moderate their platforms.
Social media is increasingly a part of our lives, our processing of information, and even a means to conduct timely research. While it has great potential, it also comes with risk attached, and misinformation is the most important aspect of that risk. Particularly given the increasing role that social media plays in our political discourse, it is increasingly imperative that users educate themselves about the risks, and that public regulation, when and where possible, attempts to mitigate them.
The research method used here was developed jointly by Mary Blankenship and Carol Graham and was made possible through Brookings Mountain West, a partnership between the Brookings Institution and the University of Nevada, Las Vegas.
Related Content



Authors


The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).



Commentary
How misinformation spreads on Twitter
July 6, 2020