

Executive summary
The influence of the online ecosystem in shaping democratic discourse is well-documented, with the expanded reach of generative artificial intelligence (AI) representing a novel challenge in a historic election year. Generative AI enables the creation of realistic images, videos, audio, or text based on user-provided prompts. Given the potential exploitation of this technology, particularly in the context of elections, it has garnered significant attention.
The transformative impact of generative AI on the information space has not matched these initial expectations. However, instances of manipulated or wholly generated content have surfaced, posing a threat to democratic discourse and electoral integrity. Addressing this challenge requires a multifaceted response.
Interventions ranging from legislative measures targeting election-specific deepfakes to voter education initiatives are imperative. Tech companies should also play a central role, including through the implementation of imperfect technical solutions to identify the origins of generated media. While these interventions may not eliminate the challenges posed by generative AI, they represent progress toward managing a complex issue during a critical election year.
Introduction
In 2024, a record number of countries will hold elections. Collectively, they are home to more than 41 percent of the world’s population and 42 percent of global GDP. Much like past elections, the online ecosystem will play a role in shaping the contours of these campaigns, but new developments have strained an already contested information space. One of these developments is the rapid advance of generative artificial intelligence (AI), which allows anyone to conjure up realistic images, video, audio, or text based on user-provided prompts or questions.
Generative AI outputs have been improving steadily for nearly a decade. However, following the viral launch of ChatGPT in November 2022, a significant amount of commentary focused on the potential for this type of content to create a “disinformation nightmare” in 2024 by accelerating the production of false information. A year after this initial frenzy, generative AI has yet to alter the information landscape as much as initially anticipated. However, even at a smaller scale, wholly generated or significantly altered content can still be—and has already been—used to undermine democratic discourse and electoral integrity in a variety of ways. Specifically, generated content tied to elections can:
- Shape last-minute attempts to deter voters from exercising their right to vote or manufacture an event featuring a generated depiction of a candidate that is difficult to debunk.
- Lead authentic information to be cast as false or generated to avoid uncomfortable questions around accountability, particularly in the face of true scandals that could impact political campaigns.
- Speed up, improve, and reduce the cost of existing information operations designed to manufacture the perception of consensus around political issues, undermine government responsiveness, sway public opinion, exacerbate divisions, demobilize or deceive voters, and undermine trust in electoral processes.
As democratic countries consider how to respond, they should evaluate a wide variety of interventions, from new or updated legislation targeted to election-specific concerns, such as the dissemination of deepfake content depicting candidates running for office, to voter education efforts aimed at teaching citizens how to scrutinize generated content. Tech companies also should play a central role by implementing imperfect but important technical solutions around content provenance and watermarking, and investing in new tools for detection. They can also facilitate knowledge-sharing across platforms from which citizens obtain their online information. Collectively, these interventions are unlikely to wholly address the challenge generative AI poses to information integrity. Yet, they are positive steps toward making a seemingly intractable challenge more manageable in a historic election year.
What is generative AI?
Generative AI is a class of artificial intelligence that takes an input—provided by a user—runs it through a pre-trained model and returns a set of expected generated outputs. Advanced generative AI leverages deep learning—an area of the broader machine learning field that uses multi-layered neural networks to generate more and more complex associations between patterns—to create images, text, videos, audio, or other content.
Generative AI relies on several foundation models within deep learning, such as generative adversarial networks and transformers, to process large amounts of data to “learn” the representation of a specific output for which the models were trained.1 ChatGPT, for example, was fine-tuned as a chatbot, while Copilot was fine-tuned to generate code, and DALL-E2 was trained to output images. The goal is to output new content that resembles the patterns learned from the training data.
Advances in deep learning, larger datasets, improved computing power, and increased investments have led to rapid improvements in output quality in just a few years.2 This culminated in the public release of chatbots such as ChatGPT and image generators such as Midjourney or DALL·E2 in 2022, which were hailed for the quality of their outputs. ChatGPT alone had more than 100 million users two months after it launched in November 2022.
All hype or an emerging threat to the information space?
Since ChatGPT’s viral launch, much commentary has focused on the potential for generated content to upend democratic elections by turbocharging the production of fabricated information. Over the past year, nearly 30,000 news articles indexed on Google News have focused on how generative AI tools might impact upcoming elections.3 Despite this interest, generated content has only been distributed sporadically online, even at times when the demand for credible information has been high and the supply of it low. Instead, recycled or decontextualized videos and images have filled this void.
In the absence of sweeping information campaigns using generated content, some have dismissed potential transformative impact of generative AI altogether. It is difficult to assess how frequently generated content is shared across social media to spread misleading information due to the diversity of channels for distributing content, lack of researcher access to data, and the increasing challenge of identifying wholly generated content. Yet there are ways to glimpse its prominence in broader conversations around information integrity, even if this type of assessment is far from comprehensive.
For example, X allows eligible users to add clarifying information to misleading posts in the form of a “Community Note.” Notes that are rated helpful are displayed alongside the post as additional context. Critically, data from the Community Notes program is made publicly available, which includes the text of the additional context users have suggested for flagged posts. As a result, we can examine the frequency with which generative AI and other related terms are referenced in this suggested context to better assess the reach of deceptive AI-generated content across X.
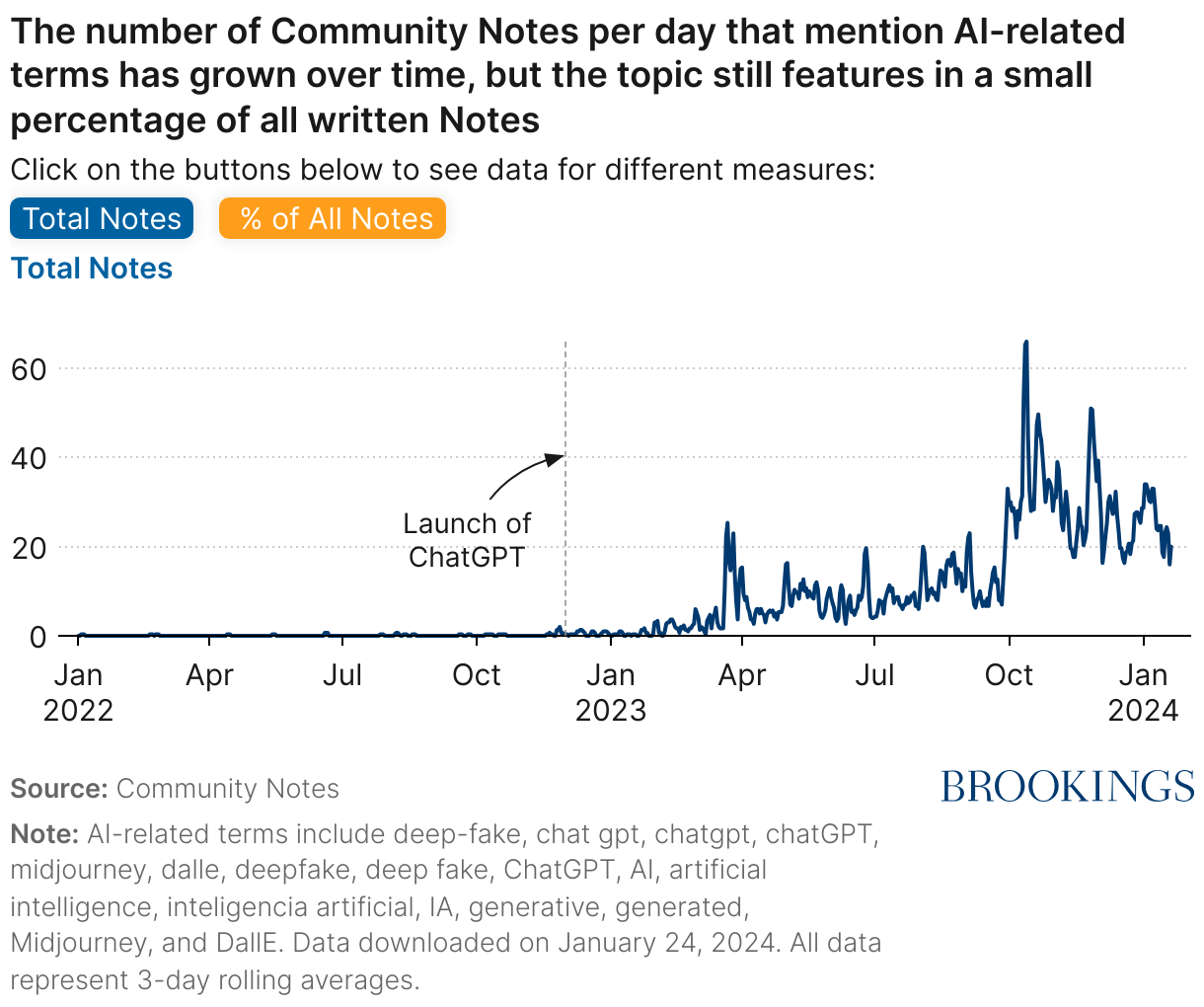
Drawing on this data, I find that since the launch of ChatGPT the number of Community Notes mentioning AI-related terms has grown over time (Figure 1, Total Notes).4 However, notes referencing these terms still only make up a little over 1 percent of the more than 300,000 notes written over the past year (Figure 1, % of All Notes).5
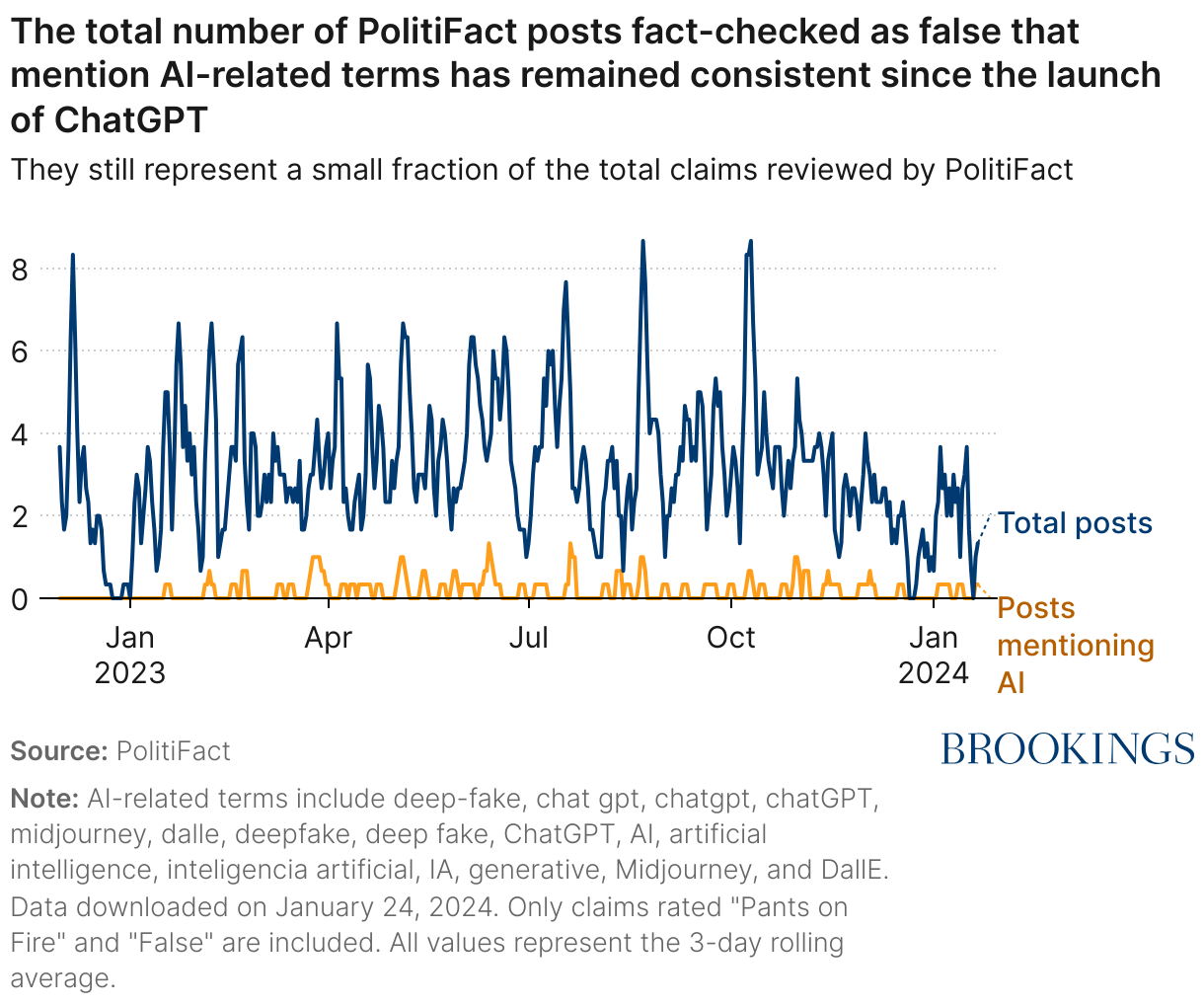
Another way to assess the extent of this challenge is to look at the number of claims evaluated by fact checkers that reference generated content. Drawing on approximately 1,300 claims fact checked as false by U.S. based fact-checking organization PolitiFact since the launch of ChatGPT, I find that 6 percent of fact-checked content references a term tied to AI-generation in their assessment of the claim. The number of posts referencing these terms has become a steady fixture over time (Figure 2), but they still represent just a small percentage of the total claims reviewed.
It is important to emphasize that neither of these cases cover all the content that circulates online. As a result, it is likely that due to capacity constraints these figures represent an undercount of the type of generated content circulating on X and across the various spaces from which PolitiFact identifies claims. Yet they also do not demonstrate an overwhelming flood of generated content across the information space. Instead, generated images, text, videos, and audio seem to complement existing, already prominent ways for disseminating false claims, which may also leverage recycled images or video.
How generative AI content has already undermined democratic discourse
Although generated content still makes up a small fraction of the overall contested information space, its usage will likely become more common, and it has already begun to undermine democratic discourse around elections. Two recent cases illustrate the unique damage even a small amount of generated content can have on the information space in the overarching context of elections.
Slovakia’s pre-election deepfake
In September 2023, generative AI-based political interference upended Slovakia’s parliamentary elections. Two days before voters cast their ballots in an election with implications for the trajectory of Slovakia’s military assistance to Ukraine and support for NATO, an audio clip which bore the markings of generated content spread widely across social media. This audio allegedly featured the voices of Michal Šimečka, leader of the pro-NATO Progressive Slovakia party, and a journalist from the daily newspaper Denník N. discussing ways to manipulate the election and buy votes from the country’s minority Roma population. Although the audio seemed suspicious from the outset, it was shared by thousands on social media, including by a former member of parliament from Slovakia’s opposition party.
Fact checkers quickly cast doubt on the authenticity of the recording due to incongruencies in the audio sound, awkward word choices, and suspicious phrase cadencing, among other anomalies. However, Slovakia’s 48-hour pre-election moratorium period, during which media outlets and politicians are compelled to stay silent and avoid election-related announcements, hindered the extensive dissemination of corrective information.
The generated audio also capitalized on a flaw in Meta’s manipulated-media policy, which explicitly addresses only wholly faked videos and not audio content. Although fact checkers were eventually able to attach a label to the post across Meta platforms, the generated audio still circulated widely in a fragmented information space where content moderation practices vary widely.
This type of last-minute scandal is particularly challenging in countries such as Slovakia, where media blackouts limit the press from discussing campaign-related content in the lead up to an election. These blackouts are typically around 24 hours but can last as long as three days in some countries. As a result, they can pose clear challenges to the debunking of viral generated content. Absent a change in election laws, social media companies must clearly delineate and enforce content moderation policies, with particular attention paid to addressing loopholes in manipulated media policies.
Argentina’s “Melcogate”
AI-generated content also played an unexpected role in Argentina’s 2023 presidential elections. A few days before the first round of voting, scandalous audio recordings began to circulate widely online. The audio recordings allegedly featured Carlos Melconian, then presidential candidate Patricia Bullrich’s pick for economy minister, speaking crudely about women and offering government positions in exchange for sexual favors.
In the aftermath of the incident, known as “Melcogate,” Bullrich and her party swiftly came to Melconian’s defense and dismissed the recordings as fabricated and potentially altered or generated using “voices and artificial intelligence.” She also questioned the source of the audio clips and attacked the journalist who shared the leaked audio, accusing him of unethical behavior in the past and of using the doctored audio as a part of a pro-incumbent smear campaign. Initially, Melconian chose to remain silent about the audio leaks. However, in subsequent interviews he did not explicitly deny the authenticity of the recordings, stating instead, “Even if it were me, what does this say? Nothing.”
It has yet to be established whether the audio clips were indeed an AI-generated deepfake. However, the incident highlights the unexpected ways that even the potential for something to be AI generated can shape the contours of an electoral contest. Moving forward, politicians will be able to reasonably dismiss true scandals as fabrications – known as “the liar’s dividend” – due to the mere possibility of credible deepfakes and other generated content. This is already happening in the United States as well, where true, old clips of former President Donald Trump have been rebranded as AI-generated. And there is some evidence that this strategy works for politicians. A recent survey experiment found that casting true scandals as “misinformation” makes voters more likely to support the implicated politician. As a result, generative AI might have its most pernicious impact in spaces where it is, in fact, not used at all. This makes it all the more critical for researchers to be equipped with the tools required to better understand the scope of the challenge, in order to avoid feeding into the hype that allows the “liar’s dividend” to find fertile ground.
Where generative AI content could influence upcoming elections
Beyond these examples, there are several avenues where generated content could make an already complex information space even more complicated. These efforts are not new: they have been the focus of election-related disinformation campaigns for some time. However, generative AI content has the potential to turbocharge campaigns designed to undermine democratic discourse by making content higher quality, more substantively distinct, and easier to mass produce than past information campaigns launched both domestically and as part of foreign influence operations.
In these contexts, generative AI content can act more as an amplifier for the spread of disinformation. Previously, these efforts required coordination between multiple actors—or even an entire troll farm—and were somewhat discoverable due to their use of recycled photos or grammatically incorrect or repetitive messaging. Now, it is possible to create large volumes of distinct content, devoid of many of these prior errors, with just a few clicks of a button.
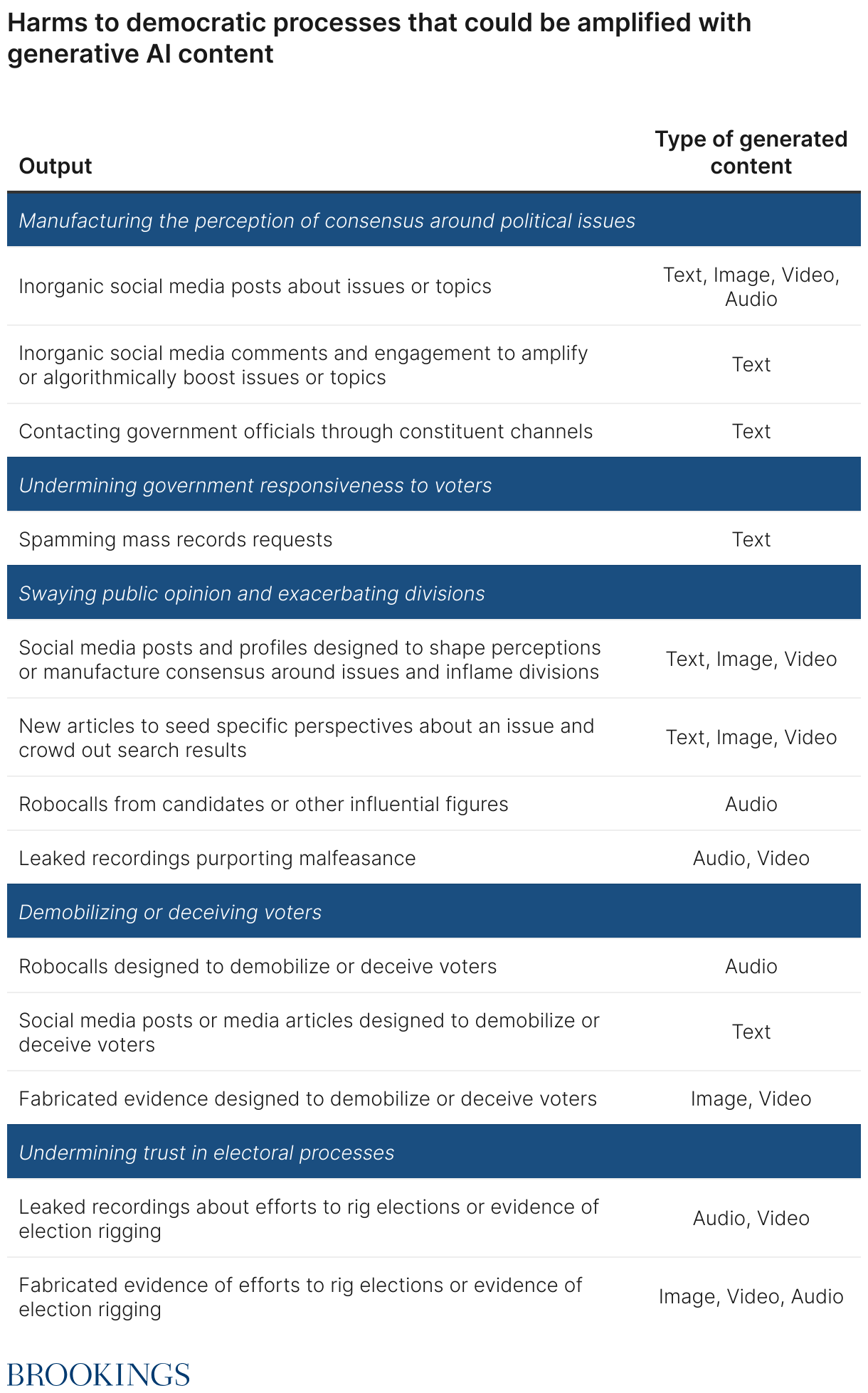
Table 1 provides an overview of different ways that generative AI could amplify or exacerbate existing threats to democratic processes. These threats include: (1) manufacturing the perception of consensus around political issues; (2) undermining government responsiveness to voters; (3) swaying public opinion and exacerbating divisions; (4) demobilizing or deceiving voters; and (5) undermining trust in electoral process.
Different types of content, from robocalls to social media posts, can and will certainly continue to circulate in the absence of generated content. But generated content may make the production of convincing outputs at scale less costly, more credible to voters around the world, and more challenging to identify and debunk.
For example, deepfakes and voice cloning have already been used to imitate candidates running for office. In one incident, an AI-generated robocall purporting to be U.S. President Joe Biden sought to discourage Democrats from voting ahead of the New Hampshire primary in the United States. Moving forward, such tactics could not only be used to more convincingly demobilize or deceive voters, but also to sway public opinion and exacerbate political divisions. Much like the Biden robocall, these efforts might be at least somewhat discoverable at the national level, but they will likely be harder to detect in state, municipal, and other local races, where resources and attention are limited.
Malicious actors also could use generated images to make influence operations and coordinated inauthentic behavior run through fake accounts more convincing. Where once these profiles relied on recycled images lifted from unsuspecting social media users, wholesale personae can now just as easily be created to make these campaigns appear more credible. Automated processes could also help to scale these fake personas in parallel more rapidly than before.
Finally, large amounts of distinct text shared on social media or through a proxy website could be used to manufacture the perception of consensus, or sow alternative narratives without some of the telltale grammatical errors and misused jargon prominent in influence operations of the past. This type of content could fill gaps online for quality information about election-related topics in specific languages spoken by minority populations and overwhelm search results that at least in part rely on the freshness of content when algorithmically ranking results. Text outputs could also be used to fabricate more credible records requests from government officials by producing slightly different outputs that make it difficult to streamline tasks. For already stretched bureaucrats and election officials, this time-intensive work could make an already challenging space even more complicated.
Other threats to the online ecosystem
Despite these clear challenges, the presence—or absence—of generative AI outputs is not in itself enough to disrupt democratic processes in an election year. The social media platforms where voters seek out information, the algorithms that govern the type of information shared, and the automated and manual review processes that scrutinize content moderation practices play an important role in shaping what voters see.
In the past year, the information space has fragmented, pushing users further and further into ideological echo chambers, with varying degrees of attention to content moderation. In some cases, discomfort with making content moderation decisions has led platforms to lean more heavily on crowdsourced solutions. Although these “wisdom of crowds” approaches can be effective, they should not be considered adequate solutions for the problems in this space, particularly given the intrinsic difficulty of detecting AI-generated content already. This challenge will likely become even more acute as AI systems continue to evolve and produce more convincing outputs.
At the same time, it has also become more difficult for researchers to access data required to explore the evolving nature of information operations in the AI era. In some cases, public APIs where researchers can collect data do not exist. In others, data access has also been severely limited by tech companies. This lack of data access limits researchers’ ability to understand the effectiveness of information campaigns, whether they are reaching their intended audience, and what role AI-generated content is playing in making them appear more credible. Without this knowledge, it is difficult to both understand the scope of the challenge and develop evidence-based responses to counteract their influence.
Strategies for defending the information space in an election year
Addressing the challenges posed by AI-generated content will require coordination across a wide range of actors, from governments to AI companies and social media platforms, as well as users. Interventions targeted toward output development, distribution, and detection will help to mitigate some of the problems generative AI poses to overall information integrity during elections. While these measures are unlikely to resolve the issues, they are positive steps in addressing a seemingly intractable challenge during a pivotal election year.
Development
Tech companies that develop AI tools are already working on strategies to better signal when an output is generated during the development process. Imperfect technological solutions include watermarking, which adds a pattern to generated content to signal that it was generated, and content provenance, which provides a layer of information, akin to a nutrition label, to help signal when an image or video was created with an AI tool, and where and how it has been subsequently edited. Watermarking for text outputs has also shown some promise. The challenge with this approach is that the outputs of highly capable models that do not opt in to watermarking or content provenance requirements might be mistaken as human generated. Additionally, while this type of metadata tagging might be helpful if it is somehow uniformly implemented across the tech industry, screenshots or phone recordings of images or videos can also remove this information, and watermarkings can easily be broken. To address challenges posed by generated content in the development phase, tech companies and legislators should consider:
- Widespread implementation of current technical solutions, and continued investment in more sophisticated approaches: Despite the limitations of technical solutions, tech companies should rapidly deploy these tools as a first line of defense against generated content tied to elections. However, while these tools are necessary, they are by no means sufficient, with mixed performance on a range of technical and policy considerations.6 As a result, continued investment in efforts to improve information about content provenance and watermarking across the industry, as well as the development of new, better solutions, will be vital to identifying generated content.
- Legislation designed to limit or build in further accountability for generated content depicting candidates actively running for office: The spread of generated content that features candidates running for office represents an immediate concern, particularly in low-resourced contexts and subnational elections. In some cases, legislation that puts guardrails—or updates existing guidelines—on the deceptive use of generated outputs that feature candidates running for office might make sense.7 However, this approach faces the challenge that politically harmful, but true content could still wrongly be deemed generated—a so-called false positive possible to many AI detectors—and generated content could be evaluated as true—a false negative. As a result, any legislative process will need to consider these clear shortcomings when assessing possible violative behavior.
- Additional user requirements to generate content featuring candidates running for office: Another possibility is for the tech companies that develop AI tools to require additional disclosures and validation processes for users seeking to generate outputs from a list of candidates actively running for office around the world. Candidates hoping to use these generators as part of their campaign could still be allowed to do so by providing additional information, but it may also allow for better tracking of deceptive generated content. This approach has the same shortcoming as watermarking efforts, namely that it cannot stop smaller-scale actors or adapted open-sourced models from producing this type of output. However, it may help address the challenges stemming from mainstream AI-generator tools, that at least for now are more likely to produce the highest quality outputs.
Distribution
Strategies that tackle the generation process are an important avenue for intervention, but so too is addressing how harmful generated content spreads. Without the ability to spread widely online, the Slovakian deepfake would have barely resonated. The reason it spread was due in part to the nature of the output—an audio recording—which bypassed Meta’s content moderation practices that focus exclusively on video-based, wholly generated media. To address these distribution-related challenges, tech companies could:
- Revisit and close loopholes in manipulated media policies of social media platforms: Social media platforms should urgently revisit their manipulated media policies to ensure they are well-equipped to contend with all types of generated content, including video, audio, and images. Companies also must decide whether these policies should incorporate partially manipulated content designed to mislead or exclusively focus on AI generation, even if the former has the same effect on voters.8
- Collaborate to better identify harmful generated content and share information across platforms: The tech companies that develop generative AI tools and the social media platforms where this type of content spreads should also collaborate to limit the widespread dissemination of harmful generated content tied to elections. A repository of recently generated political content could make it easier for social media websites to identify malicious generated political content at scale. Platforms could also use this space to share information about other AI-generated posts identified from lesser-known tools that do not participate in cross-platform collaborations. This type of approach could be similar to the hash-sharing database of the Global Internet Forum to Counter Terrorism (GIFCT), which anonymizes images and videos from known terrorist organizations into numerical representations that GIFCT member companies have removed from their platforms. This means that if generated content appears on Facebook and it is removed, it could then be securely added to a searchable database for reference by other Trust and Safety staff across different platforms, all while retaining user privacy.
The limitation of these approaches is that they require investments in Trust and Safety work and content moderation across social media platforms. Additionally, the fragmentation of the information space across many different actors—including some decentralized ones—makes this type of work more challenging due to the proliferation of additional stakeholders with varying degrees of interest in stemming the flow of malicious, generated content.
Detection
Looking further down the information pipeline, all actors—from government officials to social media platforms—should invest more in detection capabilities, which could involve technical solutions, mandated researcher access, and voter education. While these efforts will always operate in the manner of an arms race, detection efforts should not be excluded from approaches designed to mitigate the potential harms of AI-generated content, even if they will need to evolve as the capabilities of generator tools improve. Addressing these detection-related challenges may require:
- Additional research and resources to improve AI detection tools: At present, the capabilities of AI detector tools vary dramatically, and the risk of false positives and negatives is high. In tandem with research to improve the credibility of generated outputs, tech companies actively developing AI tools should invest far more in improving detection approaches to better identify generated content online, for example, of fabricated images or videos. Beyond tech company investments in this space, foundations and funders also could support research and development of these types of tools.
- Broader research access to social media data: The research community also will play a critical role in identifying the distribution patterns of generated content and offering an external view on the landscape, without some of the incentives that may shape ongoing research within the more profit-driven private sector. At present, researchers have limited access to the data required to evaluate the prevalence and impact of AI-generated content, particularly as it pertains to elections. This makes it difficult to pinpoint information operations and to assess the prevalence and scope of this challenge vis-à-vis broader trends in the information space. By understanding the extent to which generated content spreads across multiple social media platforms, researcher can provide an external assessment of the threat landscape to level-set concerns about the proliferation of this type of content, particularly when overhyping its prevalence may inadvertently facilitate a “liar’s dividend.” It will also enable the development of more tailored, evidence-based policies to promote AI’s benefits, while mitigating its harms. Legislation mandating data access by external researchers (akin to the Digital Services Act) remains critical. However, other existing proposals to simulate the online platform experience could also help facilitate research for scholars unwilling to or unable to collaborate with private sector actors. It is, however, important that these opportunities be available to researchers defined broadly—including civil society and think tank researchers—and not just those affiliated with an academic institution.
- Widespread education efforts focused on digital literacy in the AI era: It is critical for election officials, tech companies, and social media platforms to develop and widely disseminate voter education that highlights ways to approach political material skeptically, particularly given the potential for it to be wholly fabricated.9 More broadly, this education should focus on tips for identifying credible vs. generated content, sometimes known as “glitch analysis,” with the recognition that these strategies are already not foolproof and will likely become less relevant over time. For audio, this could include asking questions such as: What does the voice tone sound like? Does the pronunciation sound awkward? Is the word choice unusual or highly formal? Do pauses seem unnatural? Are there particular elements of the spoken quality of a certain language that seem off? Are there factual or grammatical mistakes? For video, this could include questions such as: Does the audio look like it is synced to the movements of the person’s mouth? Does the person depicted ever pause? What are the eyes doing during the video? Do gestures and movement seem natural? For images, the questions could include: Do the hands have an unnatural number of fingers? What does the background look like? Are accessories distorted? And do reflections in mirrors converge at a single point? These types of signals are far from infallible, and the best models are quickly learning how to address some of these issues. But, in a historic election year, they may still be useful clues as voters encounter information online.
As policymakers, tech companies and researchers continue to explore the malicious applications of AI-generated content, it is important to underscore their potential beneficial effects on elections too. For example, AI tools can help candidates reach new voters in their native language or assist with translating important campaign and election-related information into other languages, filling content gaps and data voids where false claims thrive. Given the productivity benefits of generative AI, these tools may also help less well-resourced campaigns remain competitive. In tackling any challenge related to generated content, shifts in policies and approaches should focus on the harms of these outputs, rather than whether or not the content is made using generative AI.10
Related Content
2024


-
Acknowledgements and disclosures
A portion of this report references Meta’s approach and policies relating to content moderation. Meta provides support to Brookings, but was not involved in the report’s creation. The content, findings, interpretations, and conclusions in this report are solely those of its author(s) and are not influenced by any donation. The Brookings Institution is financed through the support of a diverse array of foundations, corporations, governments, individuals, as well as an endowment. A list of donors can be found in our annual reports published online here.
-
Footnotes
- For more information on GANs, see Goodfellow, Ian, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. “Generative adversarial nets.” Advances in neural information processing systems 27 (2014). For more information on Transformers, see Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
- For some illustrative examples, see Section 3, “Recent Progress in Generative Models,” in Goldstein, Josh A., Girish Sastry, Micah Musser, Renee DiResta, Matthew Gentzel, and Katerina Sedova. “Generative language models and automated influence operations: Emerging threats and potential mitigations.” (2023).
- A Google News search conducted on January 23, 2024 of articles that reference the terms “generative AI” and “elections” from the past year returns “about 29,200 results.”
- AI-related terms include deep-fake, chat gpt, chatgpt, chatGPT, midjourney, dalle, deepfake, deep fake, ChatGPT, AI, artificial intelligence, inteligencia artificial, IA, generative, generated, Midjourney, and DallE. Data downloaded on January 24, 2024. A random sample of 200 posts flagged in an initial review as “not focused on AI-related topics” yielded no additional terms.
- For this assessment, I only evaluate notes that use the Latin alphabet. This excludes just 2.2% of all written notes.
- For an overview of the different approaches to detecting AI generated content and their performance on a range of technical and policy considerations, see: Siddarth Srinivasan, “Detecting AI Fingerprints: A Guide to Watermarking and Beyond.” Brookings Institution.
- For example, a bipartisan U.S. Senate bill, the Protect Elections from Deceptive AI Act, is designed to ban usages of AI generated content falsely depicting federal candidates in political advertisements. However, this bill is narrowly focused on advertisements, which while important, are a small fraction of the campaigning process. Several similar bills also have been proposed in the House. For a deeper discussion on this proposed legislation, see: Daniel Weiner and Lawrence Norden, “Regulating AI Deepfakes and Synthetic Media in the Political Arena,” Brennan Center for Justice. 12 Dec. 2023. This legislation could also seek to update existing laws, like the Federal Election Campaign Act, to give the Federal Election Commission (FEC) explicit power to address “fraudulent misrepresentation” through the dissemination of deceptive deepfakes. This does not address that fact that anyone could also find themselves as targets, including non-elected bureaucrats. Debates over the FEC’s role in addressing this challenge have been ongoing.
- A case selected for review by the Oversight Board will assess this possibility based on an altered video of President Joe Biden.
- On example of this is a widely disseminated video shared in the lead up to Argentina’s 2018 elections, which featured a deepfake of the candidates talking about the potential for deepfakes to circulate.
- Despite these potentially positive use cases, at present OpenAI’s Usage Policies ban the use of their API platform for “Engaging in political campaigning or lobbying, including generating campaign materials personalized to or targeted at specific demographics” as an action that could “significantly impair the safety, wellbeing, or rights of others.”
The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).


