In early February 2021, Sen. Ted Cruz and his co-host Michael Knowles were recording a live episode of the podcast Verdict with Ted Cruz when the Texas Republican coined a colorful metaphor to describe Beto O’Rourke’s base. In Cruz’s telling, the Texas Democrat’s core support is made up of “reporters” acting like “groupies at a Rolling Stones concert throwing their underwear” at him. “I mean if they wore underwear,” Cruz added. With a wry expression, he paused. “Too edgy?” he asked. Knowles laughed, dismissing the concern outright: “It’s a podcast—you can say whatever you want.”
Knowles’ assessment of the podcast ecosystem as a space where “you can say whatever you want” is—for the most part—accurate, both with respect to government regulation and platform guidelines. Even as tech companies raced to limit the spread of election-related misinformation across social media platforms in late 2020, prominent political podcasters played a central role in disseminating election fraud narratives in the lead up to January 6, as we have documented. Podcasts also offered a prime avenue for the spread of pandemic-related misinformation, particularly regarding unproven treatments and vaccines. Despite the real-world harms caused by this type of misinformation and the medium’s growing reach and influence, to-date little research has explored the role of podcasting in shaping political conversations due to a myriad of technical and other challenges.
To help policymakers, researchers, and the tech community better understand podcasting’s role in the information ecosystem, we have developed a dashboard that aggregates political podcast episode data into a single, easy-to-use format and provides an overarching look at the medium in near real time. This data set represents the first publicly available, centralized collection of podcast episode data describing the political podcasting industry in a ready-to-use, downloadable format. We focus on political podcasters, due to both their prominence in the broader media environment and their ability to rapidly shape public opinion and the contours of political debate. We hope that the release of this dashboard and data set will facilitate better monitoring of a medium that has until recently flown under the radar, despite its growing popularity and influence in political conversations.
The full dashboard and database is available here.
About the dashboard
The dashboard consists of three components: the data set, along with an accompanying codebook; weekly analyses to monitor recent trends in conversation over the past seven days; and a “build-your-own” feature that allows users to create time series plots based on a variety of filters.
The data set
The data set and dashboard we are making available today currently includes more than 40,000 podcast episodes across 79 prominent political podcasters for which episode data is publicly available. As we continue to collect data, these numbers will grow. For each episode, we include the title, description, date, and link to the audio file. We also detail why the series is featured in our data set as well as provide an estimate of the partisan leanings of the series host(s). In the codebook section of the database, we describe how we identified the 79 series included in the data set and provide more information on every data set variable.
The data set that appears online dynamically updates three times a week with new episode data to allow for better real-time monitoring of the medium. We also include additional features to allow users to filter the data set based on a range of criteria—including key words, date, and political ideology. Due to the nature of our data collection process, if an episode is removed from the show’s catalogue, it will no longer appear in our data set.
By compiling and releasing this data set, our goal is to help equip researchers with the tools to better understand and evaluate ongoing conversations across the podcasting medium in near real time. Up until this point, the podcast industry has largely been overlooked by scholars due to the highly decentralized nature of the medium and the complexity of analyzing large audio files, among other factors. As the first publicly available, centralized repository of podcast episode data, the data set and dashboard fill an important gap in the study of podcasting and aim to enable further research.
By allowing users to search episodes for main topics and themes, researchers can quickly zero in on the episodes they would like to explore further. Based on the information provided in the data set, it is easy to find episodes focused on a specific topic or theme, download the metadata, build a repository of the accompanying audio files, and run them through an AI transcription service for more in-depth analyses.
Weekly analysis
In addition to the raw data set, we also conduct several analyses on newly uploaded episodes to provide users with a breakdown of the themes and topics covered in recent episodes added to the data set. Due to the small number of podcast series classified as “Unknown” and “Moderate,” we only include episodes from podcasts classified as “More Conservative” or “More Liberal” for these figures.
We include three built-in analyses, which update regularly with the data set:
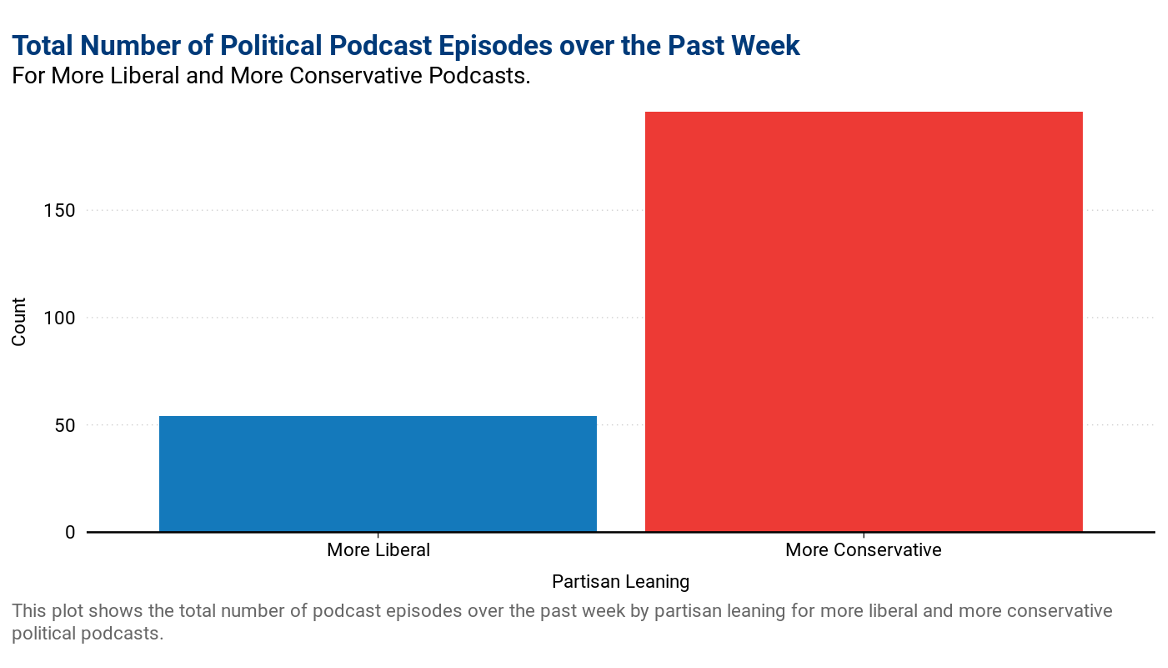
- A bar chart detailing the partisan leanings of the podcasts that have been added to the database in the past week. Of the podcasters included in our sample as of Sept. 7, the more conservative hosts recorded three times as many episodes as more liberal hosts in the last week.
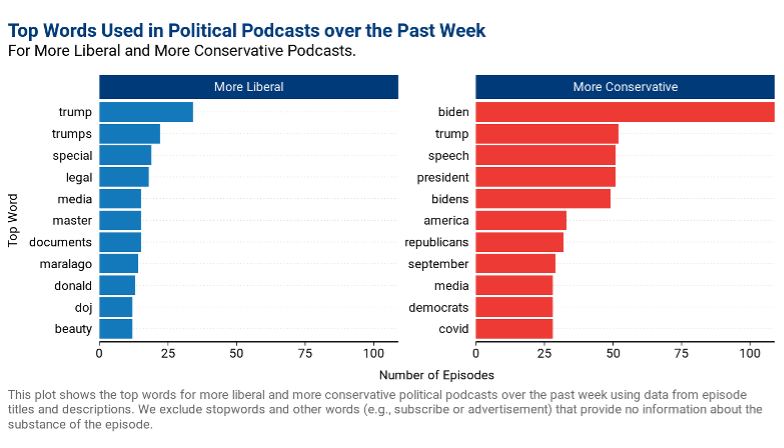
- A bar chart detailing the most popular words used in episode titles and/or descriptions by partisan leaning, which provides an indication of the topics being discussed by prominent podcasters. In the past week, the most popular word used by more liberal podcasters this week was “Trump”—an unsurprising development as podcasters continued to examine the fallout from the FBI raid on Mar-a-Lago. Although the FBI raid was also discussed frequently by more conservative podcasters, their most popular word this week was “Biden,” which based on other popular words, is likely in reference to his speech in Philadelphia.
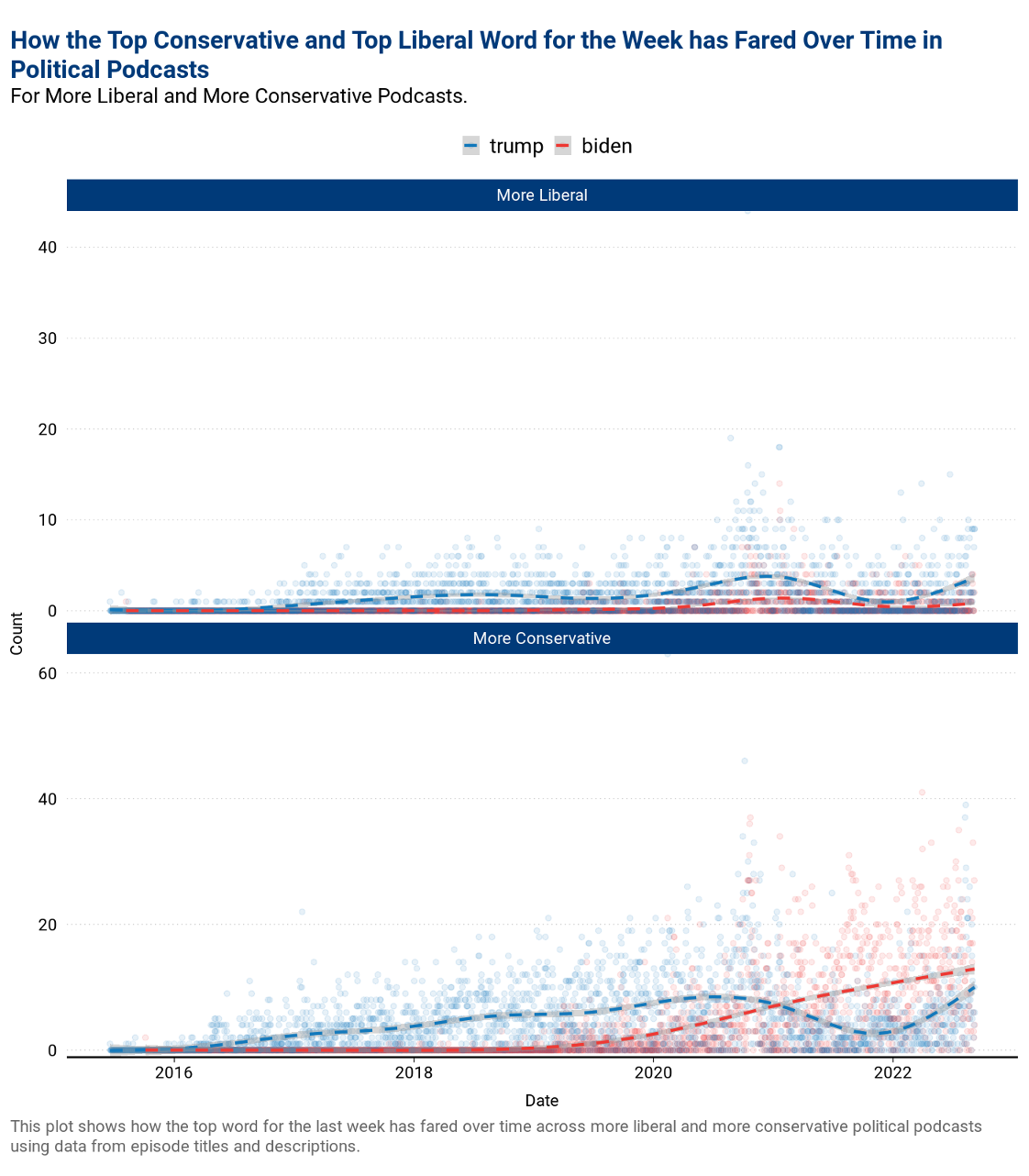
- A scatterplot detailing how the most popular word(s) for the week have fared over time by partisan leaning, allowing users to examine how the topical focus of podcasts shifts. The figure this week highlights how usage of the words “Trump” and “Biden” have changed over time for both more liberal and more conservative podcasters.
“Build-your-own” figure
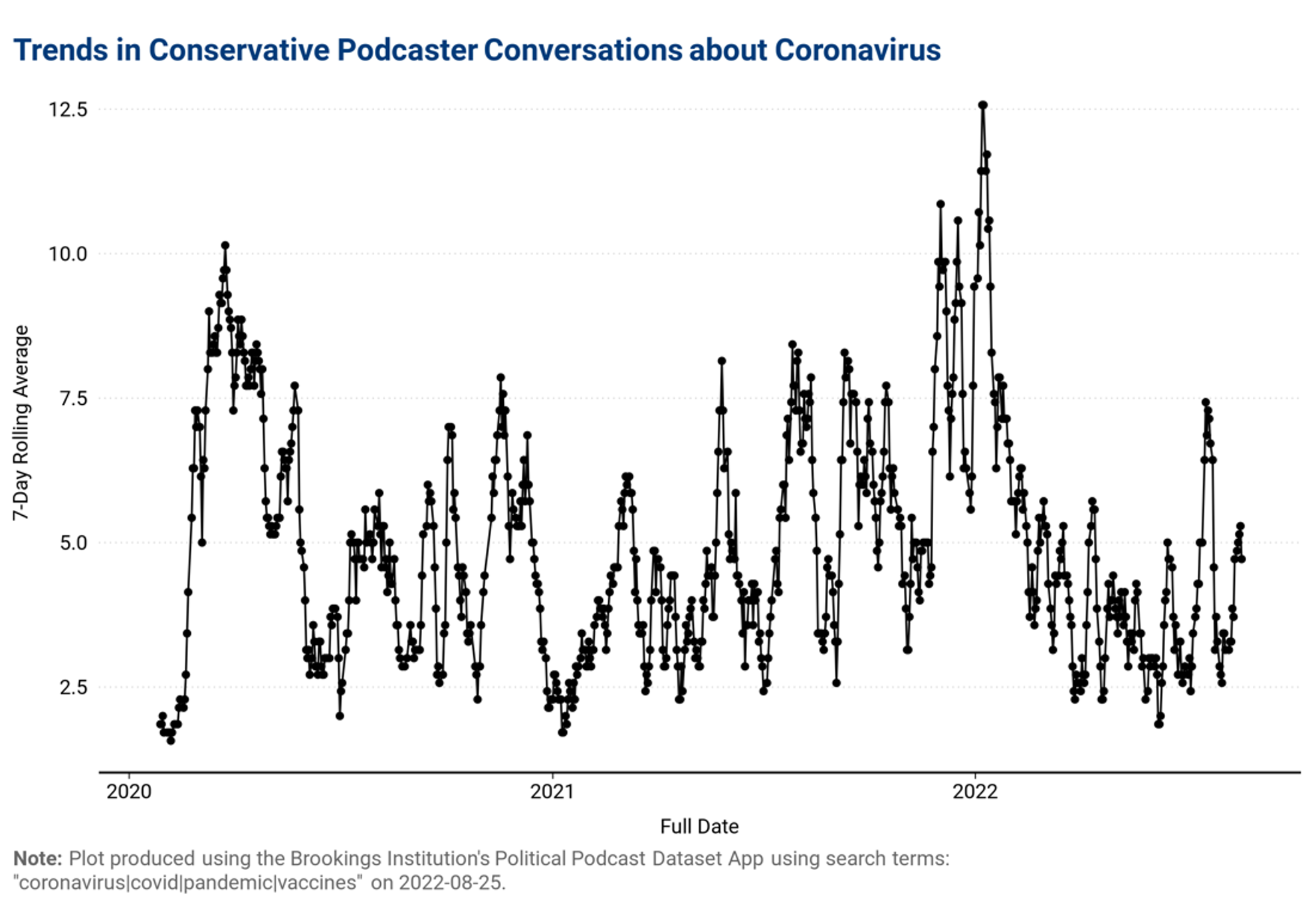
Finally, we provide an interactive feature that allows users to create custom graphics that plots the total number of episodes over time based on a variety of filters, including (1) date range for episodes; (2) partisan leaning of the series; and (3) terms or phrases used in the episode title and/or description. Users also have the option to add a title to their figure and download the data, which provides the seven-day rolling average of the number of episodes, based off their specific filters.
Below we provide an example, which examines conversations about the coronavirus over time amongst conservative podcasters, using the terms coronavirus, COVID, pandemic and vaccines. This figure illustrates how interest in the coronavirus has changed over time among conservative podcasters, with content about the virus peaking in early 2022.
Our hope is that this is just the beginning of data sharing and analysis of the political podcast ecosystem. In the future, we plan to further refine and build out this database with additional features, like transcript snippets and references to fact-checked content. We hope that you find the database useful, and we look forward to your feedback on additional features we might be able to incorporate into the application to make it an even more valuable tool for analysis of this increasingly popular and influential medium.
Valerie Wirtschafter is a senior data analyst in the Artificial Intelligence and Emerging Technology Initiative at the Brookings Institution. She received her Ph.D. in Political Science from the University of California, Los Angeles.
The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).



Commentary
A new data set for better monitoring of the political podcast ecosystem
September 7, 2022