

David Leonhardt’s recent article about the Federal government’s efforts to use research to be more effective got me thinking about teacher evaluation systems. Leonhardt notes that criticisms of research-driven efforts to improve government often say measurement is hard, “as if that were a reason to skip it.” Sara Mead echoes the point in a recent post, when she writes, “education is far more complex than many areas of human endeavor and inquiry. Yet when we mistake this complexity for immeasurability, we are in trouble.”
For jobs that produce tangible units, measuring an employee’s effectiveness is straightforward. K-12 teaching ranks high among occupations for which there are no tangible units and for which measuring effectiveness is a challenge. (It’s challenging for college teachers too, but let’s focus on K-12.) What is the output we want to measure? Well, ‘good’ education, but we need to be more specific. In the past decade, most of the U.S. has decided that teachers (and schools) will be evaluated on how well they provide a ‘good education’ by using test scores and formal observations of teachers in their classrooms.
New Evaluation Systems
Currently, 40 states and the District of Columbia have systems that measure how effective their teachers are that at least partly depend on student test scores. The two largest states, California and Texas, are among the 10 that don’t, but the direction is clear.
Because test scores naturally will be higher when students are more proficient, many of these new systems use changes in test scores to measure teacher effectiveness, which is called ‘value added.’ A student had a certain test score last year and has a certain test score this year; roughly speaking, the difference between those two scores is ‘value added.’ Kids learn from others beside their teacher, including: other kids and teachers, parents and siblings, friends, churches, the local YMCA, and social media, to name a few. And some kids live in less affluent households, or have a problem or disability that affects learning. Value added teacher evaluation systems need to use statistical models to adjust for these other influences.
It’s useful to remind ourselves what system these more technical approaches are replacing. The previously dominant method of teacher evaluation relied on principals observing teachers in classrooms. Generally, a tenured teacher was observed twice in a year. A 2009 analysis found that in a sample of school districts, principals rated 99 percent of teachers as satisfactory. Everybody passed the test. This phenomenon has come to be known as the ‘widget effect.’ Since teachers are considered equally effective, they are viewed as interchangeable widgets. The same analysis also reported that 43 percent of teachers in those districts believed there was at least one tenured teacher in their school who should be dismissed for poor performance, suggesting even teachers realized the system rating them was lenient. Moving toward a more systematic approach based on value added and formal classroom observations is a big change from drive-by principal observations, and it recognizes the common-sense notion that teacher capabilities differ and information to help them improve their teaching is useful.
Most evaluation systems are so new there is little research on them, but a recent paper on the District of Columbia’s IMPACT system by Thomas Dee and James Wyckoff provides some insights about what happens under a new system. The district historically has performed poorly while spending about twice the national average of per-pupil spending. IMPACT was introduced as part of reform efforts that emerged after DC moved to mayoral control in 2007. The system is based on classroom observations and, for teachers in grades 4-8, test scores. Five annual observations are done by principals and by outside observers, all of whom are trained how to conduct the observations. Test scores are used in a sophisticated statistical model, and account for 50 percent of a teacher’s IMPACT score. The proportion of DC teachers who work in grades 4-8 is comparatively small, but for those teachers, value added is heavily weighted in their evaluation score. Dee and Wyckoff focused on the value added component of the IMPACT system, and thus, so will I. For research on the classroom observation component of new evaluation systems, see this 2014 report by my colleagues Russ Whitehurst and Matthew Chingos.
The value added element of the IMPACT system produced clear incentives. If a teacher received a very low IMPACT rating two years in a row, he would be discharged from the district. Thus, after receiving the first low rating, he had an incentive to either improve his teaching or to leave the district. On the other hand, if a teacher received a ‘highly effective’ rating two years in a row, he would receive a pay raise.
Dee and Wyckoff analyzed data on whether DC teachers remained in the district and whether their students’ test scores improved the year after they received their IMPACT ratings. Dee and Wyckoff used a ‘regression discontinuity’ design, a clumsy term for an elegant method. It relies on the logic that individuals who are close to but on different sides of a threshold typically share a lot of characteristics, so comparing what happens to the two groups (the group immediately below the threshold and the group immediately above it) yields insights about behavior induced by the threshold.
Dee and Wyckoff found that low-rated teachers were more likely to leave the district, and highly-rated teachers were more likely to improve their students’ test scores the year after getting their first ‘highly effective’ rating. No matter what job we are talking about, I think a reasonable person will agree that these are desirable outcomes of an evaluation system. And the findings show that teachers responded to the system’s incentives.
Information for Teachers
Teachers’ unions have resisted the use of test scores for teacher evaluation. The AFT recently called using test scores to evaluate teachers part of a ‘test and punish’ model. If by ‘punish’ the AFT means that teachers who are demonstrably ineffective at teaching choose or are encouraged to leave their teaching job—in DC this proved to be 15 percent of teachers—it’s an odd use of the word. Aren’t ineffective teachers actually punishing students and their parents?
But teachers’ unions have a point about urging that evaluation systems be ‘transparent and readily understandable.’ If I were a teacher, I probably would not embrace these new evaluation systems because I wouldn’t know what they were really doing. For example, New Jersey recently implemented its new teacher evaluation system without providing much information to teachers. A curious teacher will look in vain for an explanation of the system on the state’s Web page. The page is full of links to other places one can go to get more information, as if links on a Web page explain anything. The experience is like reaching an automated voice that goes through a lot of menus that don’t answer your question, and never to a human.
New Jersey is just one state, but other states are not much clearer about their evaluation systems, either. Like New Jersey, Colorado’s Web page shows links about its teacher evaluation system, but the links do not explain it. A link to a video shows girls high jumping to explain its model. It also has a link to a white paper that statistical wonks might like. The National Council on Teacher Quality (NCTQ) gives its highest rating among states to Florida for its policies to support effective teaching. But the Florida state page only links to other information, with no explanation of its teacher-evaluation system. Following one of the links leads to another technical white paper, different from the Colorado one, which statistical wonks also might like.
The Tennessee page demonstrates that states can provide helpful information about these complex methods. Tennessee has the longest history of using test scores for evaluating teachers. It introduced its ‘TVAAS’ system in 1993. The state’s Web page has accessible and useful information about the system in general, and its ‘resources’ page links to a 10-minute video prepared by the University of Wisconsin Value Added Research Center illustrating how statistical models remove background factors from measures of teacher effectiveness.
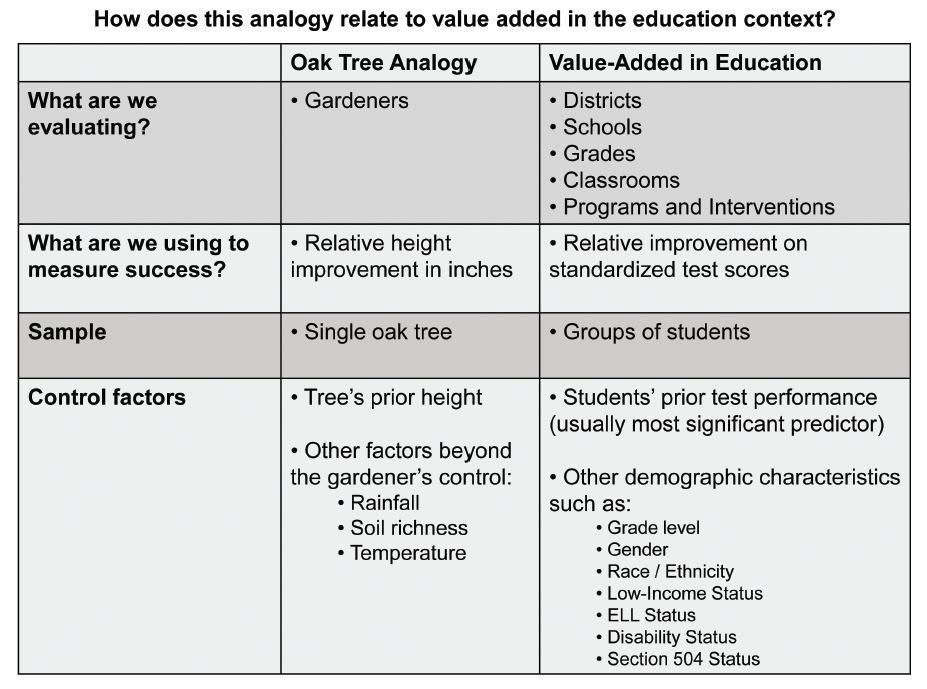
Reprinted with permission of the Value Added Research Center at the University of Wisconsin
The graphic above illustrates what’s in the video, which uses a metaphor of two gardeners and the trees they grow to explain how value added models compare two teachers and the students in their classrooms. Curiously, though, Tennessee does not use the value-added modeling approach shown in the video. Even after more than two decades, the state’s web page stops short of a complete explanation.
Teachers are in the middle of a sharp change in how they are evaluated. At one time, it was casual and had a known result (remember: 99 percent satisfactory). Now, it’s technical. A stronger scientific basis for evaluating teachers is a good thing, but the scientific community needs to work with policymakers to inform teachers how the systems work, and to identify what these systems can and cannot do. Changing how millions of teachers are evaluated is a big thing, and explaining it seems like due process.
I don’t think we should skip measuring teacher effectiveness, but I think we can explain it better.
The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).


