

The Obama administration is moving full steam ahead with its plan to rate colleges, with public hearings beginning today and the goal of releasing a draft ratings system in the spring that will be finalized by December 2014. The White House plans to gauge the performance of colleges based on three categories of measures:
- Access, such as how many students receive Pell grants
- Affordability, such as tuition, scholarships, and debt burdens
- Outcomes, such as graduation rates, earnings, and advanced degree attainment
The specific methodology used to generate ratings of college quality is always subject to debate. Beth Akers and I have outlined the technical challenges facing the effort to rate colleges based on student outcomes, and I have also detailed the reasons that “comparison groups” are a subpar approach.
Even if a perfect methodology did exist, it would be worthless without access to good data. Clare McCann of the New American Foundation has described the significant limitations of existing data on colleges, such as the omission of part-time students from graduation rate data and the federal ban on linking student-level data across different sources, as the “elephant in the room” of the White House plan.
Some fear that building a ratings system on limited data will undermine the effort. Stanford economist Caroline Hoxby told the New York Times, “I do not believe the federal government currently has the capacity to generate a ratings system that will even be neutral. I think it’s more likely that it will be harmful to students.” Hoxby’s criticism centers on both the lack of good data on student outcomes such as earnings linked to where the student went to college, and the lack of data on differences in colleges’ student bodies that need to be taken into account.
The latter concern—that we don’t have the necessary data to make apples-to-apples comparisons—is a crucial point that is rarely discussed. As Hoxby explained to the Times, “Let’s say you looked at Harvard, Yale, [and] Stanford. You’d say they have all these great outcomes. But that doesn’t necessarily mean that’s the value added by those colleges, because their students were terrific.”
Fairly comparing different colleges requires taking into account aspects of the student body that are related to outcomes such as graduation rates and earnings. Academic preparation is the most important factor to adjust for in order to identify the institutions that provide better educational experiences rather than those that simply enroll better-prepared students. The annual U.S. News rankings received well-deserved scorn for rewarding colleges for attracting students with better test scores and penalizing those that attract students who are more challenging to educate.
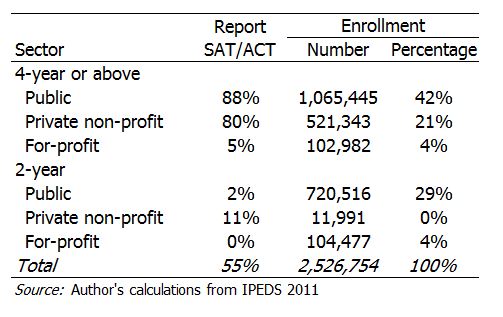
The problem is that the only measure of academic preparation available is the average SAT or ACT score of the entering class, and these data are not available for all institutions. The table below shows that although SAT and ACT scores are reported by most four-year institutions outside the for-profit sector, very few two-year colleges collect data on SAT or ACT scores. All told, nearly half of American college students attend an institution that does not report this information—and thus could not be rated in a way that takes into account student academic preparation. Many of these institutions (such as community colleges) could not collect this information if they wanted to, because many of their students do not take the SAT or ACT.
There is a second problem. SAT and ACT scores are a very poor measure of academic preparation at most colleges, limiting their usefulness even at the institutions where they are available. In our 2009 book, Crossing the Finish Line, Bill Bowen, Mike McPherson, and I show that if two students have similar high school grades but different SAT or ACT scores, at most colleges the student with the higher test score is no more likely to graduate, on average, than the student with the lower score. SAT and ACT scores may be more useful when used as an average for each college, but their weak predictive power at the individual level is troubling.
When measures of academic preparation are not available, a popular alternative is to instead take into account the demographic characteristics of the student body, such as Pell grant eligibility, race/ethnicity, and gender. These characteristics are often correlated with academic preparation, and thus stand in as weak proxies for it. However, using such factors in ratings formulas implicitly sets different expectations for different groups of students. For example, if Pell-eligible students tend to have lower graduation rates than other students, colleges that enroll more Pell students are rated more leniently.
A potential improvement is on the horizon in the form of new assessments being developed to measure student readiness for college and careers as part of the Common Core standards effort. (For more on the cost and quality of these new tests, see my new Brown Center report, “Standardized Testing and the Common Core Standards: You Get What You Pay For?”) If these tests succeed in accurately measuring college readiness—or at least exceed the low bar set by the SAT and ACT—they could vastly increase the potential of college ratings systems by providing a measure of academic preparation for all students. But that requires an additional big if: the ability to link the scores to where students go to college. And the new tests will not be taken by students until 2015, so the results could not be matched to college students until a few years later.
A high-quality ratings system will require significant changes to the data collected by the federal government, including a radical overhaul of IPEDS, measures of college readiness, data that drill down from the campus level to the program level, and a creative strategy to link college graduates to their labor market outcomes. These changes cannot be accomplished on the Obama administration’s announced timeline, so is the administration putting the ratings cart before the information horse?
There is a clear case to be made for the federal government using its authority to gather data like these for postsecondary institutions that receive taxpayer funding, but little precedent for the government producing ratings. The Securities and Exchange Commission regulates stocks and bonds, but leaves it to private organizations to rate them. The Department of Transportation sets standards for the calculation of cars’ gas mileage, but does not opine on whether a Ford is better than a Toyota. The Food and Drug Administration decides which pharmaceuticals can be sold in the U.S., but does not say whether Advil is better for a headache than Tylenol.
In the coming year, we are likely to hear a lot about how we should not let the perfect be the enemy of the good. Education Secretary Arne Duncan recently said, “Data is always imperfect and we will use the best data we have” and that the ratings would be improved “as better data becomes available.” The administration will likely argue that students need access to better information on colleges now, and that its ratings system will combine the limited information that currently exists into college quality metrics that are more useful than the rankings produced by the private sector.
Whether such a ratings system will do more harm than good is an open question that we are likely to see answered in real-time in the coming years. But one thing is clear: whatever simplistic system is developed over the next year should be accompanied by a clear plan for the ambitious upgrades to data collection efforts needed to enable the creation—whether by the government or private entities—of more robust ratings systems. If the Obama administration can make serious progress on the thorny data issues, that well may end up being a much more lasting contribution to higher education policy than the actual ratings system.
The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).


