
Background
Artificial intelligence (AI) shows tremendous promise for applications in health care. Tools such as machine learning algorithms, artificial neural networks, and generative AI (e.g., Large Language Models) have the potential to aid with tasks such as diagnosis, treatment planning, and resource management. However, their ultimate impact on health outcomes will be shaped not only by the sophistication of the tools themselves, but by external “human factors” as well.
Foremost among these are the data utilized in building AI tools; inaccurate, inappropriate, or incomplete data can result in poor performance—often in ways that are not anticipated by designers or transparent to users. Broadly, the datasets used by developers to train AI tools can have key gaps which can cause AI responses that are lower quality or even potentially harmful for some users or situations. These pitfalls are well-known among experts, but the extent to which they will hinder specific applications of AI in health care remains unclear.
Other ways in which applying AI to health care might unexpectedly produce diluted or even negative outcomes are less widely discussed. Social factors that determine who uses AI tools and what actions they take in response to interactions with them will shape the impact of AI on health care. Underpinning these social factors are trust and social influence. Evidence suggests that there may be an initial skepticism among many potential users who may be particularly hesitant to trust AI for consequential decisions that affect their health. In addition, attitudes may differ within the population based on attributes such as age and familiarity with technology. Direct experience with AI tools (positive or negative) can alter users’ opinions about their trustworthiness. Similarly, indirect experiences can affect perceptions, as people communicate their opinions of AI tools to others and change their own views based on what they learn through social interactions.
Because the stakes are high, we want to proactively anticipate ways in which applications of AI to health care might fall short of expectations and consider ways to mitigate such circumstances. We are presented with two major challenges. First, these applications are nascent, and so we have little data to guide us. And second, the questions that we are asking are inherently complex in nature: there is a high degree of heterogeneity (among individuals and contexts) and interdependence (between them) inherent in the intersection of AI, health care, and social dynamics.
To overcome these obstacles, we developed a simple Agent-based Model (ABM), a simulation tool that allows us to conduct computer-assisted “thought experiments.” We use our ABM to consider the problem abstractly (i.e., without relying on any real-world data) while also capturing dynamic implications for populations in a sophisticated manner. Here, we summarize initial insights we have gained into the conditions under which AI tools might fail to improve overall population health, introduce health disparities, or leave existing inequities in place.
Learn more about our ABM below.
Major Findings
Result 1: In order to have positive impact on population health, an AI tool might have to be highly accurate. Failing to reach this standard, an objectively accurate health care AI tool can potentially produce negative health outcomes if its performance is perceived as underwhelming by users.
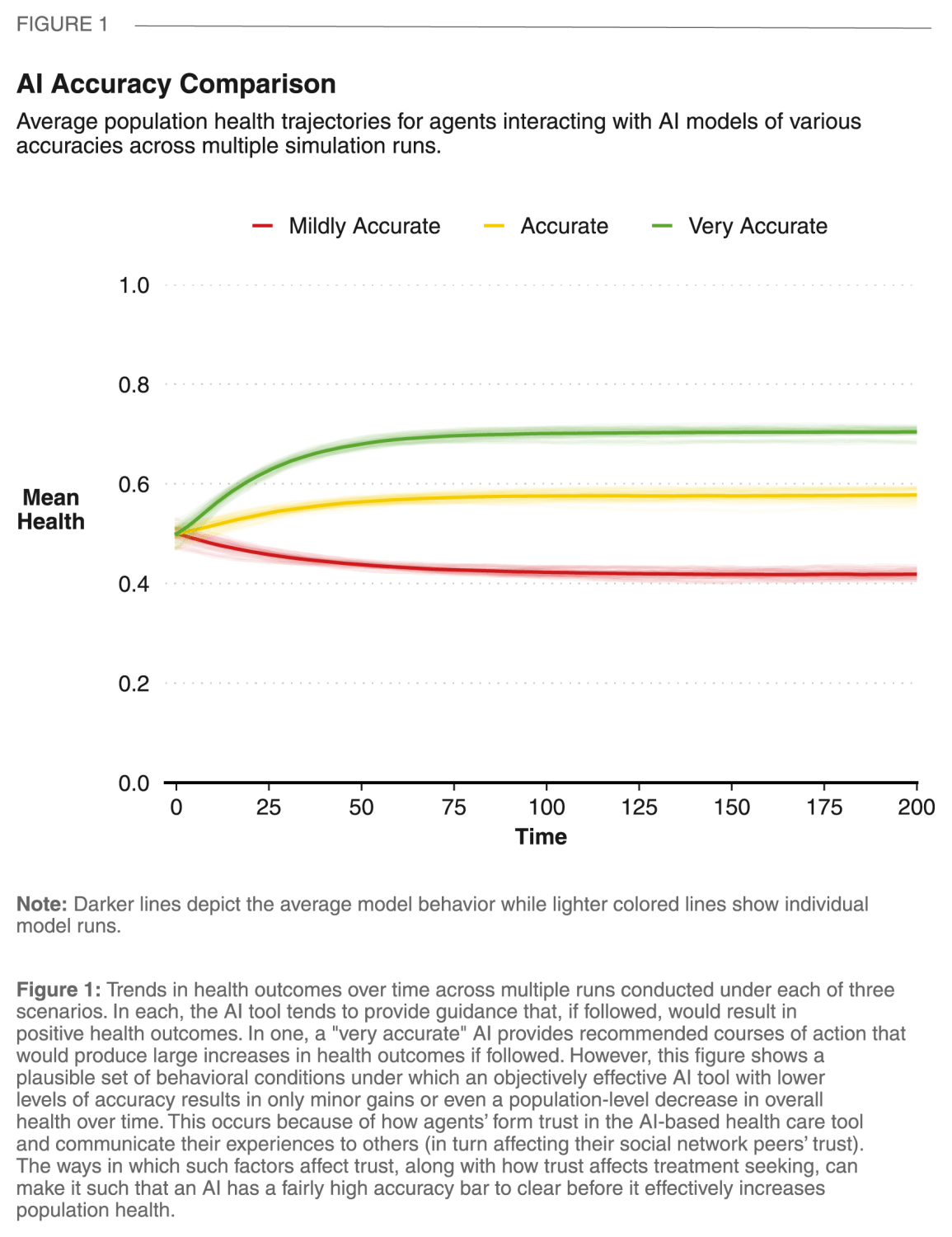
It is possible that human factors can result in surprising effects when applying AI tools to health care. In particular, the process through which an individual’s experiences with an AI tool are filtered through their expectations and then shared with others plays an important role. Here, we have a simulated population with moderate initial trust in the tool, but can reshape their views over time based on their own experiences and what they learn from others. Under these plausible starting conditions, an accurate or very accurate AI tends to produce population-level health increases (trends over time shown in yellow and green in Figure 1, respectively). However, a mildly accurate AI that, on average, provides treatment recommendations that would have positive effects for users if followed, can nonetheless have an overall negative impact on population health (the red line in Figure 1). The key to this dynamic is in user expectations and social influence. Although objectively positive—in expectation, the AI won’t give recommendations that are harmful or completely ineffective—if treatment quality is sufficiently lower than expectations, users will let their social network peers know, who in turn will adjust their own trust (and expectations) downward. With an AI that tends to give only slightly helpful guidance, initial levels of trust erode as modest expectations are frequently disappointed. As this sentiment spreads through the community, reticence to engage with the tool can cause a gradual decline in population health.
Result 2: Even an objectively accurate health care AI tool can worsen health disparities if its performance differs across users and is perceived as underwhelming by some.
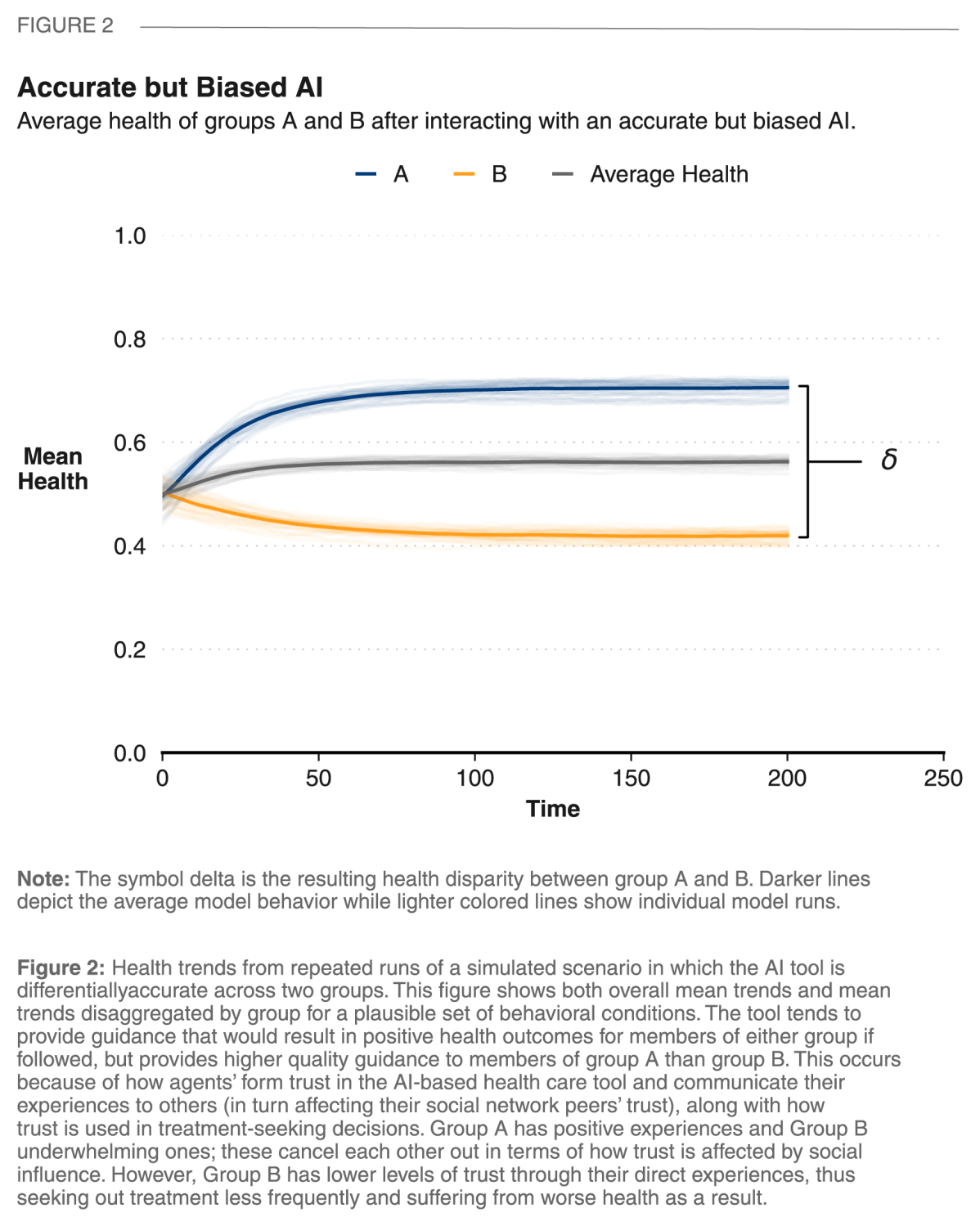
Figure 2 shows a dynamic that can occur when an overall highly accurate AI performs differentially across groups within the population. Here the AI’s recommendations tend to be high in quality for members of one group (group A), and lower in quality for members of the other (group B). These differences in direct experiences with the AI drive down trust levels in group B, which in turn will make them less likely to engage with the AI tool. Given the differences in the experiences and subsequent behaviors across groups, we see an overall population-level health increase generated by benefits for members of group A along with an underlying introduction of health disparities between groups.
Result 3: If differences in initial trust in AI-based health care are present in a community, these may be hard to overcome and, as they drive different use patterns, might alone contribute to widening health disparities as AI is introduced. Unfavorable social conditions within communities can exacerbate the impact of biased AI tools on health disparities.
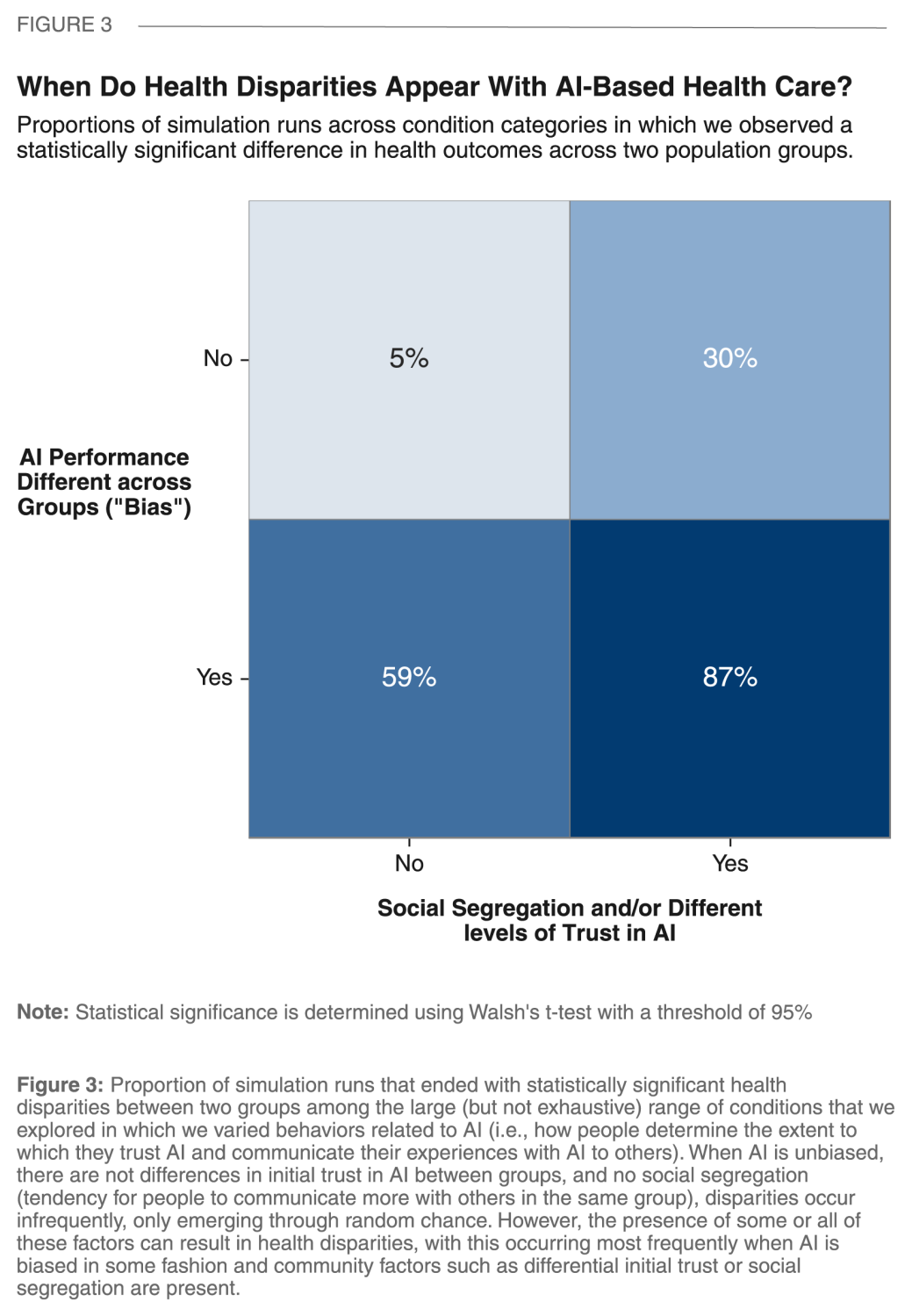
We used our ABM to conduct “computer-assisted thought experiments” to consider the possible ways in which applications of AI tools to health care might go awry. We focused our attention on two categories of “human factors” that can result in undesirable health outcomes: different types of AI bias and social differences between groups—specifically systematic patterns of skepticism toward AI tools and social segregation.
Figure 3 summarizes the large number of simulations that we conducted across a wide range of plausible conditions, categorizing each simulation run by the presence or absence of any sort of AI bias or social difference between groups within a community. As anticipated, the absence of both (shown in the upper left quadrant of Figure 3) is associated with health disparities between groups that appear only through random chance (i.e., “false positives” detected by the statistical test that we employ).
Interestingly, as we see in the upper right quadrant of Figure 3, it is possible that a highly accurate and completely unbiased AI tool (i.e., one that in expectation, tends to provide all users with similarly helpful treatment recommendations) might still introduce health disparities. Specifically, when there are initial differences between groups in their trust of AI-based health care—for example because of one group’s systematically negative previous experiences with health care or due to the AI tool being poorly communicated to one group—differential use patterns alone can translate into meaningful differences in health patterns across groups.
As discussed above and shown in the bottom left quadrant of Figure 3, biased AI performance across groups can create health disparities. However, the largest cause for concern is the simultaneous presence of both unfavorable social conditions and AI bias creating conditions where health disparities are highly likely to emerge (bottom right quadrant of Figure 3).
Recommendations
Although our experiments give us a first look at whether health disparities might emerge given specific AI or community conditions, they are predicated on hypothetical scenarios. We have little data to inform either the frequency or form of biases that might exist in AI tools that will be be applied to health care tasks in the future. Similarly, we have little guidance on the social conditions related to the application of AI-based health care in real-world settings. Based on what we have seen here and what we know that we don’t know, we have identified three recommendations for policymakers, AI developers, health care workers, and researchers that can help proactively prevent unintended negative consequences of applying AI-based health care tools.
- Consider potential pitfalls early in the process. The health impact of AI tools can be constrained if the data used to train them don’t sufficiently mirror diversity in the populations in which they will be deployed. Even tools that are effective in the aggregate can end up introducing and worsening disparities. Therefore, it is incumbent upon those creating and preparing these tools for use to carefully consider whether the training and testing data used are representative across a wide variety of groups that might experience disparate impact. Categories to consider include (but are certainly not limited to) age, gender, culture, ethnicity, socioeconomic status, education, and language fluency. Given that the consequences of deleterious impact are so costly, it is also worth investing a substantial amount of time and resources to conduct pilot tests to assess performance across groups before large-scale application. Data resulting from these studies can also be used as inputs into ABMs like the one that we employ here to prospectively gauge when, and in what ways, an AI tool may have suboptimal impact when applied to a wide range of real-world settings and user behavior patterns.
- Proactively explore social contexts and behavioral factors related to AI. As our simulations show, the impact of AI tools on health outcomes can be highly dependent on social factors that are, at present, poorly understood. It is worth engaging in prospective data collection and subsequent qualitative and quantitative research to learn more about how people might think about AI tools, shape one another’s perceptions, choose to engage with AI tools, and respond to guidance from these tools.
- Continue thinking about long-term effects. The simulation model that we developed to explore how the impact of applying AI tools to health care might be moderated by social factors is a first step on a journey that we believe should be ongoing. Future, more advanced models that consider additional factors or respond to new data can provide further insights. For example, our ABM considers group affiliation in a very abstract way, with two groups that are differentiated but intentionally left undefined. A more realistic treatment of important social and demographic heterogeneity in future applications is almost certainly warranted. Additionally, our model considers activity within relatively short time horizons within which the effectiveness of AI tools does not change. However, the longer-term co-evolution of AI and human behavior is worth exploring in future work. Similarly, this initial model treats AI-based health care as a homogenous presence. In future work, it will be important to develop more sophisticated models that can provide insight into how AI-based health care might differ based on deployment by health care professionals, utilization by patients, and the emergence of multiple AI tools.
About the Model
We developed an Agent-based Model (ABM) to explore some of the possible unintended consequences resulting from applications of artificial intelligence (AI) to health care tasks. ABM is a “bottom-up” computational simulation approach in which the behavior of individual entities (“agents”) as well as their interactions with one another and their environment over time drive population-level trends. Here, we provide both an animation and a textual summary of our ABM. A complete description can be found in our report and supplementary materials.
Model Overview
Agent Behavior
Our model represents a hypothetical community of individuals receiving health care that is based on an artificial intelligence (AI) tool designed to provide medical recommendations. Simulated individuals (“agents”) in our model have one of two different group affiliations (either “A” or “B”). This categorization is intended to abstractly represent a meaningful social categorization or combination of categorizations (e.g., race, gender, income, education, age cohort, etc.) along which AI bias can occur, trust of AI-based health care tools might initially differ, or a tendency to form within-group social connections might take place.
Agents each have properties denoting their health and their current level of trust in the AI tool. As time progresses in the model, the health of agents slowly deteriorates, reflecting natural age-related processes, occurrence of illnesses, and injury. In addition to this entropy, all agents have ongoing opportunities over time to interact with the AI, doing so through a set of serial decisions, actions, and effects:
- Seek Treatment. Agents choose whether to seek treatment from the AI health care tool. This decision is influenced by an agent’s current health and current trust, with both lower health and greater trust increasing the chance of seeking treatment. If an agent chooses to seek treatment, they will consult the AI and receive a treatment recommendation.
- Adhere to Treatment. For medical advice to have an impact on health, the patient must follow it (“adhere”). In the real world, there are many factors associated with adherence (e.g., treatment cost or unpleasantness). In our model, we focus on a single one that is of immediate relevance: trust in the health care provider. An agent will choose to adhere to the recommendation they receive in proportion to their trust in AI tool.
- Health Outcome. Adherence to a treatment recommendation will affect an agent’s health, with the effect dependent on the quality of the recommendation for the agent’s health status. As discussed below, quality of recommendations is a continuous value that is probabilistically sampled each instance from a distribution that is based on AI characteristics. Thus, a highly accurate AI is likely to give high-quality recommendations that can improve health by a large amount, while a highly inaccurate one may frequently give low-quality advice that can have a negative effect on health. An agent’s health outcome from a treatment recommendation will in turn influence their trust of the AI—recommendations that increased health can increase an agent’s trust of the AI and vice versa. Initial interactions with the AI will influence an agent’s trust more than those later on, reflecting both a large body of social science literature on opinion formation and the common adage that “a first impression is a lasting one.”
- Social Influence on Other’s Trust. Every agent has social connections to a small number of other agents in the model. For every given simulation run, agents are randomly placed in a social network with a high degree of clustering (i.e., as in many real-world settings, there are many mutual friends in the social network). After experiencing a treatment outcome, an agent may share information about the effectiveness of the AI with their social contacts. If the treatment recommendation exceeds the agent’s expectation of the AI (which is based on trust), the trust of the agents that they are socially connected to will increase. Similarly, if the AI underperforms, the agent will share this information, decreasing the trust of the agents to whom they are socially connected.
AI Impact
The way in which each AI recommendation will affect an agent’s health if followed is determined by randomly sampling from a predefined impact distribution. Our ABM allows us to control this distribution to conduct thought experiments connecting AI performance to health outcomes in three ways:
- Average Accuracy: Allows for the adjustment of the quality of medical recommendations made by the model, which affects how much (and in what direction) average population health tends to change after adhering to a recommendation.
- Variance: Allows for the adjustment of how variable the quality of AI recommendations are (i.e., the range of prediction accuracy). For example, do model recommendations consistently have the same accuracy or do they span a large range of accuracies?
- Skew: We can adjust whether and to what extent the distribution is left-skewed. The presence of skew results in the AI occasionally experiencing “catastrophic failure,” cases in which recommendations, if followed, result in very bad health outcomes.
Experimental Design
We use our model to conduct a large—but far from exhaustive—set of experiments to explore the potential impact of AI-based health care under a range of hypothetical scenarios. Our primary goal is to gain intuition into how different AI tools might shape health outcomes across a range of settings. Therefore, we have developed our model such that we can manipulate AI tool performance and social settings across simulated scenarios as follows.
AI tools
We first define a baseline AI with a distribution of recommendation quality such that average expected impact will be an increase in agents’ health, but positive health effects are not guaranteed. We then vary from this baseline to explore potential impacts of AI bias. Specifically, we use our model to explore all combinations of the presence or absence of three types of potential bias that might conceivably occur due to limited or inconsistent training of the AI training with data that are more relevant for some users than others:
- Differential mean accuracy: Recommendations for group A are sampled from a distribution with higher mean accuracy than group B (i.e., group A tends to receive recommendations that would result in better health outcomes if followed)
- Differential variance: Recommendations for group A are sampled from a distribution with lower variance than group B (i.e., there is less “noise” in the provision of recommendations to group A)
- Differential skew: Recommendations for group A are sampled from a distribution with no skew while recommendations for group B are sampled from a distribution with a high degree of left skew (i.e., members of group B have a greater chance of encountering rare instances of “catastrophic failure” in which they receive recommendations that would have negative health consequences if followed).
Social Settings
We define social settings according to the presence or absence of two characteristics. The first is social segregation, which increases the frequency of same-group social connections and results in most communication comprising social influence on agents’ trust in AI occurring between individuals who belong to the same group. Second, we allow for levels of trust to potentially differ between groups, with the possibility that trust begins substantially lower for group B than A. Such systematic differences might plausibly arise for a variety of reasons, including familiarity with technology in general or AI in particular; previous experiences within health care settings, especially with discrimination, stereotyping, stigma, or exclusion; and whether and how the use of a specific AI tool has been communicated.
Authors



-
Acknowledgements and disclosures
The authors would like to thank Sanjay Patnaik for his careful review and helpful comments, Stephanie Aaronson for her feedback, and Chris Miller for design assistance.
The Brookings Institution is financed through the support of a diverse array of foundations, corporations, governments, individuals, as well as an endowment. A list of donors can be found in our annual reports published online here. The findings, interpretations, and conclusions in this report are solely those of its author(s) and are not influenced by any donation.
The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).


