Within two months of its launch last fall, the popular chatbot ChatGPT had reached an estimated 100 million monthly users—making it the fastest growing consumer application in history. Now that its parent company OpenAI has released a new version of the chatbot’s underlying language model, anyone with access to the app will soon be able not only to write poetry and practice journalism, but even ace the LSAT and GRE. Like most leading-edge language applications today, ChatGPT relies on a machine learning algorithm known as a transformer to generate probability distributions over words and then recognize, translate, predict, or generate text. The quality of that text is often deeply impressive—so much so that even relatively restrained tech publications have concluded ChatGPT may be “coming for your job.”
Yet large language models may disrupt far more than just the economy. They also appear poised to challenge democracy too. At issue is not just the risk of automated misinformation campaigns, but the threat to traditional forms of democratic engagement. Democracy depends in part on how responsive those who govern are to the preferences of the governed: from public comments on proposed agency rules (“submit your comments and let your voice be heard,” exhorts regulations.gov) to legislators’ refashioned electronic mail boxes, citizens have long offered feedback to policymakers via the written word. By making it trivial to produce large quantities of credible text, language models threaten to weaken the signal those words provide. As the New Yorker recently observed, ChatGPT “will strain a political system in peril.”
The threat is far from an idle one. In 2017, the Federal Communications Commission (FCC) invited public commentary regarding its proposed changes to net neutrality regulations. An orchestrated astroturf campaign opposed to net neutrality soon flooded the comment line, generating more than 8 million comments, while a single college student in favor of net neutrality used an automated script to generate seven million comments of his own. The government foiled the attempt only because of the inadequacy of the technology: since only 6% of the 21.7 million comments were unique and seven comments alone accounted for 38% of all submissions, the manipulation was easy to detect. By contrast, language models capable of automating unique submissions at scale will not be as easy to uncover.
To gauge the extent of the problem, we ran an experiment on the impact of language models on the efficacy of congressional correspondence. More specifically, we examined whether language models could distort the legislative agenda by drafting limitless original emails to members of Congress. Using both human writers and GPT-3, OpenAI’s predecessor to the GPT-4 system it announced last week, we randomly sent email to over 7,000 state legislators around the country and then compared response rates. The difference in response rates, which scholars use as a proxy for government responsiveness to constituent concerns, was just 2% overall, with no differences in response rates for three of the policy issues we analyzed. The findings suggest that legislators are potentially susceptible to the misuse of these technologies.
Research design and methodology
To investigate the possible misuse of language models like ChatGPT, we conducted a field experiment in 2020 using OpenAI’s then-state-of-the-art language model, GPT-3. We selected six policy issues—gun control, reproductive rights, education, health care, policing, and taxes—and asked a number of undergraduate research assistants to write right and left-leaning advocacy letters. We then trained GPT-3 on the student letters and asked GPT-3 to write new letters advancing a right-wing and left-wing position on each issue. For example, here’s the first paragraph of a right-wing gun control letter that one of our research assistants wrote:
I was recently appalled by an interview on the News with the co-founder of Students for Safer Schools. He insisted that it was a natural consequence of our current gun control laws to allow active shooters to commit mass murder in schools. I am writing this letter in order to implore you to oppose any bill to ban or curtail the rights of gun owners in America.
Based on this student sample, we asked GPT-3 to “write a right-wing letter on gun control.” Here’s the first paragraph of the AI-written letter:
I hope this letter finds you well. I would first like to thank you for the job you’ve done in representing us in this time of national turmoil. The pandemic and social unrest sweeping the nation right now have made life difficult for all, and many citizens, myself included, fear that our Second Amendment right to firearm ownership may become more and more of a necessity in daily life.
Next, we created a program on Python to alternately send either human or AI-written emails to roughly 7,200 state legislators. All told, we sent a total of 32,398 emails or approximately 5 per legislator.
We then compared response rates to human and AI-generated emails as a measure of how credible each type of email was. Given the competing demands on a legislator’s time, the decision to answer a constituent letter implies a calculus about the importance of responsiveness to that individual or issue. Previous studies seeking to understand whether legislators discriminate on the basis of constituent race or ethnicity have sent emails from Hispanic, Black, or Muslim aliases and looked for differential response rates as evidence of discrimination. In our case, we judged that a busy legislator would not respond to a message that was clearly robotic or nonsensical, but rather would reply preferentially to real constituents.
Our analysis suggested that legislators found the AI-generated text almost as credible as the human-written messages. On two issues – gun control and health policy – we found virtually identical response rates for human versus machine emails (See Figure 1). And on a third, education policy, we observed a higher response rate for the machine-generated emails, though the difference is not statistically significant. This suggests that on these issues GPT-3 succeeded in producing content that was almost indistinguishable in the eyes of state legislative offices from human content. By contrast, legislators were less responsive to machine-generated communications on three issues: policing; reproductive rights; and taxes. However, even on these issues legislators responded to GPT-3-generated emails at rates only 4% lower than to hand-written emails.
Figure 1: Differential Response Rates (GPT-3 – Human Emails) by Policy Area
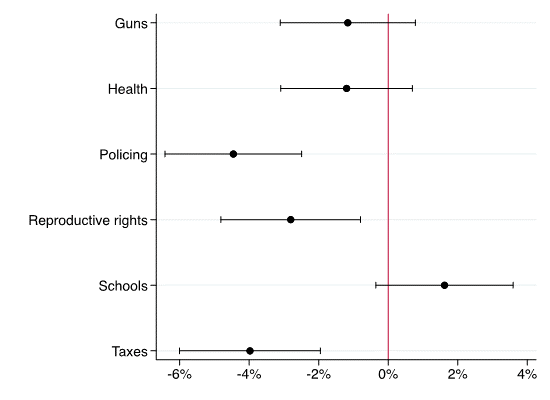
While our findings suggest legislators routinely failed to distinguish real from AI-manufactured communications, follow-up exchanges with legislators surfaced some helpful tips for guarding against manipulation. Even the best language models can produce bland, generic, or sometimes factually inaccurate content, or can “hallucinate” and become repetitive. For example, one email started, “My name is Rebecca Johnson, and I am a single father raising a daughter.” This raised a red flag for at least one legislator in our sample. Further, the machine sometimes struggled to write ideologically consistent letters, particularly from a right-wing perspective on the issue of gun control. For instance, one AI-generated letter began, “I am a rifle owner and hunter”—but then suggested that the author took a turn and argued that owning a firearm was a constitutional right.
Even if these inconsistencies occur in a small fraction of the outputs, avoiding them requires a human-in-the-loop that is at odds with a nefarious actor’s goal of automating malice. The same antidote to these low-quality outputs also undermines the potential misuse of these tools. Of course, as the technology improves—such as through reinforcement learning from human feedback, or RLHF—those types of outputs will become less prevalent. Nevertheless, for now legislators or staffers should look for these hallmarks—or even better, the absence of telltale residency markers like specifics about the district or state.
Policy implications of generative AI
What then is a legislator to do? Mail has always been an important way that politicians from local representatives to presidents have kept tabs on public opinion. Even in an era of ubiquitous polling, many have viewed mail as informative of the concerned public on a given issue—the effort it takes to compose a letter or note has historically served as a strong signal of the salience of a given issue or policy proposal, particularly when multiple constituents touch on the same points. However, language models threaten to weaken that signal. As malicious actors leverage them in a bid to influence the behavior of policymakers and regulators, elected and non-elected officials alike will have strong incentives to be skeptical of the information they can glean about public preferences from both constituent feedback and correspondence.
Fortunately, legislators have other means of keeping their finger on the pulse of public opinion. With enough resources, they can obtain district polling data on key issues; alternately, they can hold more frequent and more targeted town meetings to get a direct earful from those most animated about an issue. As the capacity for astroturfing increases, legislators may have to rely more heavily on these other sources of information about constituency preferences—and discount the sheer volume of text that they previously took as a signal of public attitudes.
In addition, regulators and legislators may also soon be able to more readily detect auto-generated text. For one, the same algorithms underlying models like GPT-3 can also be adapted to identify machine-generated text; researchers have shown that the accuracy of machine-based detection of generated text can reach accuracy rates of close to 90%. For another, OpenAI, Anthropic, and other labs responsible for leading-edge language models are all now experimenting with statistically watermarking the text they produce. As consensus standards and tools around watermarking emerge, legislators and regulators may be able to filter their correspondence through software that identifies auto-generated content. Finally, as language models improve, agency and congressional staff will need to rely on greater digital literacy to understand the risks they pose.
Recent election cycles have made it clear that malicious actors are both willing and able to leverage digital applications to subvert American democracy. With the advent of powerful new language models, those actors now have a potent new weapon in their arsenal. Lawmakers and regulators will need to work proactively to guard against the risks they introduce.
Sarah Kreps is a Non-Resident Senior Fellow in the Brookings Foreign Policy Program and the Brookings Artificial Intelligence and Emerging Technology Initiative, as well as the Director of the Tech Policy Institute at Cornell University.
Douglas Kriner is the Clinton Rossiter Professor in American Institutions and faculty director of the Institute of Politics and Global Affairs at Cornell University.
Microsoft, a major partner and investor in OpenAI, provides financial support to the Brookings Institution. The findings, interpretations, and conclusions posted in this piece are solely those of the authors and are not influenced by any donation.
The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).


Commentary
How generative AI impacts democratic engagement
March 21, 2023