Few things are as vital to democracy as the free flow of information. If an enlightened citizenry is essential for democracy, as Thomas Jefferson suggested, then citizens need to a way to be kept informed. For most of the modern era, that role has been played by the press—and especially the editors and producers who exercise control over what news to publish and air.
Yet as the flow of information has changed, the distribution and consumption of news has increasingly shifted away from traditional media and toward social media and digital platforms, with over a quarter of Americans now getting news from YouTube alone and more than half from social media. Whereas editors once decided which stories should receive the broadest reach, today recommender systems determine what content users encounter on online platforms—and what information enjoys mass distribution. As a result, the recommender systems underlying these platforms—and the recommendation algorithms and trained models they encompass—have acquired newfound importance. If accurate and reliable information is the lifeblood of democracy, recommender systems increasingly serve as its heart.
As recommender systems have grown to occupy a central role in society, a growing body of scholarship has documented potential links between these systems and a range of harms—from the spread of hate speech, to foreign propaganda, to political extremism. Nonetheless, the models themselves remain poorly understood, among both the public and the policy communities tasked with regulating and overseeing them. Given both their outsized importance and the need for informed oversight, this article aims to demystify recommender systems by walking through how they have evolved and how modern recommendation algorithms and models work. The goal is to offer researchers and policymakers a baseline from which they can ultimately make informed decisions about how to oversee and govern them.
Why digital platforms rely on recommender systems
Suppose you run a social media or digital platform. Each time your users open your app, you want to show them compelling content within a second. How would you go about surfacing that content?
The quickest and most efficient approach is just to sort content by time. Since most social networks and digital platforms have a large back catalogue of content, the most recent or “freshest” content is more likely to be compelling than content drawn at random. Simply displaying the most recent items in reverse-chronological order is thus a good place to start. As a bonus, this approach is both easy to implement and straightforward to understand—your users will always have a clear sense of why they are seeing a given piece of content and an accurate mental model of how the app behaves. While the industry has moved beyond them, reverse-chronological recommendation algorithms powered the first generation of social media feeds and are why most feeds are still known today as “timelines.”
While appealing in their simplicity, purely reverse-chronological feeds have a massive downside: They don’t scale well. As platforms expand, the amount of content they host grows exponentially, but a user’s free time does not. The most recently added content will therefore serve as a less and less effective proxy for the most compelling content. Worse, users who want to build a wide audience will flood the platform with new content in a bid to stay at the top of other users’ feeds. As a result, your app will quickly become biased to the most active users rather than the most interesting ones. Less engaging content—or even outright spam—will start to inundate user timelines.
To address that problem, you could craft hard-coded rules to prioritize among the most recent content. For instance, you could write a rule that says: If Nicole has liked posts from Dia more than any other user, then show Nicole Dia’s latest post from today before anything else. Or you could write a rule that says: If Nicole liked video more than any other form of content, then the most recently added video from her friends should be shown to Nicol first, before any other content. By mixing and matching these manual rules, attribute- and category-based recommendation algorithms can more reliably surface compelling content than a purely reverse-chronological feed.
However, relying on hand-coded rules also has its drawbacks. It forces developers to bake in a lot of assumptions about what users will be most interested in, many of which may not actually be true. Do users always like video more than text? And when a user likes a given post, do they always want to see more from its author? So long as a recommendation algorithm is purely hand-coded, the algorithms will be biased toward developers’ assumptions about what users are most interested in viewing.This approach also doesn’t scale well: The more rules are manually added, each incremental new rule will be less effective and make the codebase more difficult to maintain.
At a certain size, the best approach for efficiently surfacing compelling content is to rely on machine learning. By drawing on past user data, deep learning recommendation algorithms—and the deep learning recommendation models trained on them—have proven particularly effective at “learning” what content users will find compelling and to surface it for them. Every major platform now relies on some version of deep learning to choose what content to display, but these approaches come at a cost: Whereas reverse-chronological algorithms are easy to implement and understand, large-scale deep learning algorithms are complex to implement and effectively impossible to comprehend and interpret.
Which recommendation algorithm works best for your platform will depend on tradeoffs between performance, cost, and interpretability, or how easy it is to identify why the algorithm is behaving in a certain way. For large social networks and digital platforms, the performance gains of deep learning recommendation algorithms far outweigh both the cost of developing them and the corresponding decline in interpretability.
While that tradeoff may make users more likely to continue engaging with content on the platform, it has important externalities for democratic societies. In the United States alone, researchers have documented how recommender systems clearly exposed users to far-right extremist movements, as well as conspiracy theories regarding COVID-19 and the outcome of the 2020 election. Despite the role recommender systems played in spreading content related to those movements and narratives—which have been instrumental in fomenting recent political violence—they nonetheless remain poorly understood by both policymakers and the public. Understanding how the technology works is thus a vital first step toward an “enlightened citizenry” capable of governing it.
How recommender systems work on digital platforms
Although the details vary slightly by platform, large-scale recommender systems generally follow the same basic steps. As Figure 1 shows, recommender systems typically first produce an inventory of available content and then filter it in line with their content moderation policies, after which they pare the inventory down to only the items users are most likely to be interested in.
Figure 1: Recommender systems overview
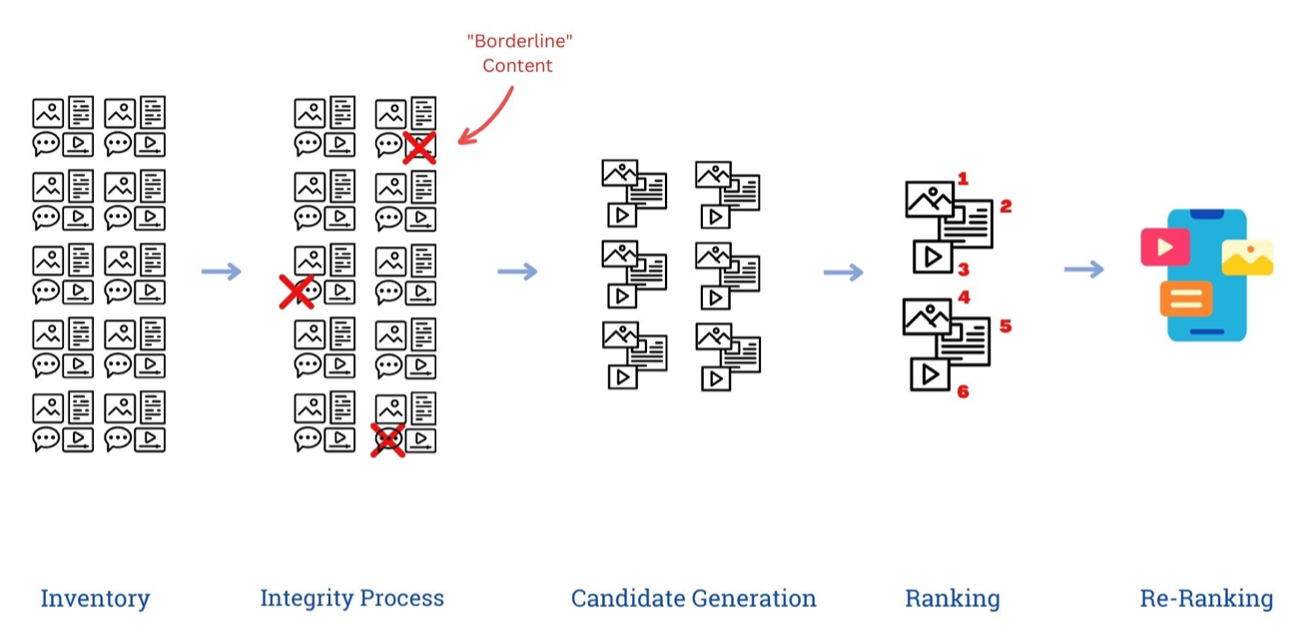
- Inventory. In the first step, a recommender system will compile an inventory or catalog of all content and user activity available to be shown to a user. For a social network, the inventory may include all the content and activity—posts, likes, shares, etc.—of every account a user follows or has friended. For a video platform, the inventory could include every video that has ever been uploaded and set to public. For a music app, it could be every song it has the rights to play. For digital platforms, the catalog of available content is often enormous: As of early 2020, users on YouTube alone were uploading 500 hours of video every minute—or 720,000 hours daily and a staggering 260 million hours annually, the equivalent of 30,000 years.
- Integrity processes. The largest digital platforms have developed complex moderation policies both for what content may be published and what can be shared or amplified. Once the inventory has been compiled, it needs to be scanned for content in violation of these policies and for so-called “borderline” content, or items that can be published but not shared (or at least not shared widely). Typically, this includes text, video, or audio that is known not to violate the platform’s term of service but that the platform has reason to believe may be problematic or offensive.
- Candidate generation. After checking to ensure the inventory doesn’t include content that shouldn’t be shared, recommender systems will then carry out a “candidate generation” or “retrieval” step, reducing the thousands, millions, or even billions of pieces of content available in the inventory to a more manageable number. Since ranking every piece of content in the inventory would be prohibitively expensive and time intensive, most platforms instead rely on what’s called an “approximate nearest neighbor” (ANN) search. Rather than ranking each piece of content, an ANN typically grabs dozens or hundreds of items that are likely in the ballpark of a users’ revealed preferences and interests. Not every video will be a great fit, but it’s a fast and loose way to quickly compile a decent sample of “candidate” items to display.
- Ranking. After the full inventory of content has been narrowed to a more manageable size, the candidates are then rank-ordered. As discussed in more depth below, this typically involves training a deep learning recommendation model to estimate the likelihood that the user will engage with the content in some way (e.g., by liking or commenting on it).
- Re-ranking. Although ranking algorithms have improved dramatically over the past decade, they are not perfect. Since they rank individual items on their own rather than the feed overall, the final ranked list may include a particular type of content (e.g., video) too many times in a row or recommend content liked or authored by the same person over and over again. As a result, a “post-ranking” or “re-ranking” step, which typically draws on hand-coded rules, is needed to ensure a diversity of content types and authors appear within the items selected for display.
In recent years, many of the policy conversations around mitigating the harms linked to digital platforms have focused on the integrity step—especially the content moderation policies that determine whether a piece of content can be published or shared—but far greater attention needs to be paid to the ranking step. If in fact recommender systems are having a significant impact on everything from electoral integrity to public health, then the process by which recommender systems sort and rank content matter a great deal as well. By better understanding the complex system behind content ranking, policymakers will be in a better position to oversee their use.
How ranking algorithms function
Although social media platforms architect their ranking algorithms slightly differently than other digital platforms, in general nearly all large platforms now use a variant of what is known as a “two towers” architecture to rank items.
To see what that means in practice, imagine you have two different spreadsheets. The first is a spreadsheet where every row is a user, and every column is a user attribute (e.g., age, location, search history). In the second spreadsheet, every row is a piece of content, and every column is a content attribute (e.g., content type, title, number of likes). By modeling the information in each spreadsheet in separate parts of a deep neural network—an algorithm whose structure is (very) loosely analogous to the way neurons connect in the brain—a “two-towers” approach learns over time the likelihood of whether a given user will engage with a particular piece of content.
Figure 2: Growth in deep learning model parameters
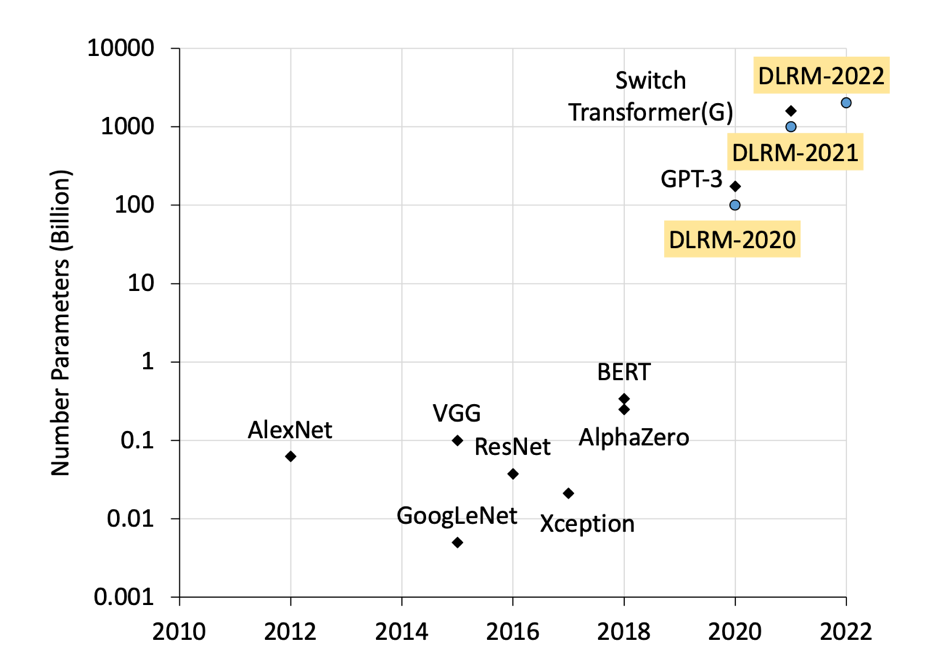
Although this approach has proven remarkably successful, platforms with a large user base and a deep catalogue of content end up needing to train models that are exceedingly large. A platform with a billion users and a trillion pieces of content, for instance, would need to learn a model capable of efficiently generalizing to 10^21 potential user-item pairs, a challenge made all the more daunting by the fact that most users never engage with the vast majority of content. As a result, they need to include an extraordinarily large number of model parameters, or “neurons” in a neural network, to perform well across so many different user-item pairs. Recommendation algorithms are much larger than other forms of deep learning for this reason. Whereas GPT-3, a powerful large language model released in 2020 by OpenAI, had 175 billion parameters, or “neurons” in its deep neural network, the recommendation model powering Facebook’s newsfeed has 12 trillion parameters. With so many parameters, it is effectively impossible to understand and reason about how the model behaves merely by examining the trained model itself.
Implications
The architecture of modern recommender systems has important implications for policymakers and the public at large, yet they may not be obvious to non-technical audiences. The following implications are especially important:
- The outcome metric matters. A lot. As noted above, deep learning recommendation algorithms typically try to learn a model that predicts how likely a given user is to engage with a given piece of content in some way, such as by liking or commenting on it. Since content with a strong emotional valence—such as a birth announcement or a scathing political diatribe—is likely to elicit greater engagement, models may learn on their own to prioritize sensational content. When it comes to political content in particular, they risk becoming confirmation bias machines and driving greater polarization. Which outcomes a model is trained on has significant implications for how they will behave.
- They are too large to explain and interpret. Despite recent progress in explainable and interpretable machine learning, the behavior of large deep learning recommendation models still far exceeds our ability to comprehend. If reverse-chronological newsfeeds are preferable insofar as users can perfectly understand and reason about them, then recommendation models that rely on deep learning are the polar opposite. As noted above, with models as large as 12 trillion parameters, there is no way to reliably identify why a given recommender system made a particular recommendation.
- Frequent retraining and model updates make evaluation a challenge. Deep learning recommendation models are not as strictly focused on time as reverse-chronological feeds, but their ability to surface relevant content will degrade over time if they are not retrained using new and more recent data. As a result, they are retrained on a frequent basis, which may lead to changes in their behavior. In addition, most large platforms frequently push out updates to the overall model architecture. Between the frequent updates to a model’s architecture and the need to retrain existing models frequently, systematically evaluating recommender systems over time can be challenging.
- Algorithmic impacts cannot be assessed via auditing the underlying code and trained model alone. The size and opacity of deep learning recommendation models mean that reading each line of code in the underlying algorithm or examining each trained parameter, or “weight”, will not be particularly useful for understanding how it behaves. If the goal is to understand the impact of recommender systems on individuals and society, then policymakers who call for full access to the algorithms and model weights would be better served calling for researcher access to model outputs instead. Seeing what content a model actually recommends in response to a given set of inputs for a given user is far more important for understanding the model’s behavior and societal effects than scanning through individual lines of code.
Conclusion
Since the architecture of large recommender systems makes it difficult to understand how they behave, finding better ways to evaluate their behavior is vital. Regulators, researchers, and the technology industry can all take steps to better evaluate models. From platform-researcher collaborations to simulated environments and other privacy-preserving techniques, it is possible to gain greater clarity on the behavior and impact of recommender systems than we currently enjoy.
Seizing those opportunities will be ever more vital as recommender systems continue to grow in importance. TikTok, a viral video app, recently eclipsed Google in internet traffic largely by virtue of its improved recommender system, which surfaces content from across the entire app’s userbase rather than just a user’s connections. In response, social media platforms like Facebook and Twitter have started to similarly expand the “inventory” initially surfaced by their recommender systems to include more content from across the entire platform. Mark Zuckerberg, for example, recently said that he expects that by 2023 more than 30% of the items in a user’s feed on Instagram and Facebook will come from accounts a user has not friended or followed. As other platforms rush to keep pace, they too will all but certainly increase their reliance on purely recommended content.
In turn, the potential impact of recommender systems on democratic societies will only grow—as will the importance of understanding how they work.
Chris Meserole is a fellow in Foreign Policy at the Brookings Institution and director of research for the Brookings Artificial Intelligence and Emerging Technology Initiative.
Facebook and Google provide financial support to the Brookings Institution, a nonprofit organization devoted to rigorous, independent, in-depth public policy research.
The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).



Commentary
How do recommender systems work on digital platforms?
September 21, 2022