
Read the full report published by the Center for European Policy Studies (CEPS) here. The author would like to thank Adelle Patten from the Brookings Institution for the illustrations used in this blog post.
Governments around the world are considering how to regulate algorithmic systems as their societal impact expands and deepens. This is partially a reaction to the widening use of machine learning (ML), an algorithmic approach that uses historical data to learn (or “train”) a set of patterns. These patterns are stored in an ML model which can then be used to make predictions, such as which advertisements will be more effective for a specific viewer. Many recent computational achievements have relied on the field of ML, such as mastery of the game Go, more convincing chatbots, and more realistic computer-generated images.
As the use of ML expands, new commercial approaches to ML are emerging, including several that separate parts of the ML development process across multiple companies or organizations. This has led to consideration of the ML “value chain,” which is the organizational process through which an individual ML model is developed and then put into use. This focus on the organizational process distinguishes the ML value chain from the technological steps of building an ML model.
As policymakers look to tackle challenges such as discrimination, explainability, and fraud, they cannot be ignorant about, or agnostic to, how different businesses implement ML value chains. This policy brief proposes seven distinct approaches to the ML value chain—an early attempt to categorize emerging business models of ML. These different approaches have varying levels of risk and significant implications for creating effective algorithmic oversight. Especially important is ascribing accountability by ascertaining which organization is responsible for the decisions made by ML models when multiple organizations are involved. Further, the categorization helps illuminate how some approaches, especially those with significant divisions of ML model development across multiple organizations, present elevated risk of harms.
Seven approaches to the ML value chain
(1) Internal deployment—A company that writes the code for, fully trains, and then deploys an ML model for internal use within a company’s function. An example of this scenario is a model that manages and allocates tasks to warehouse employees, developed and implemented solely by the warehouse operator.

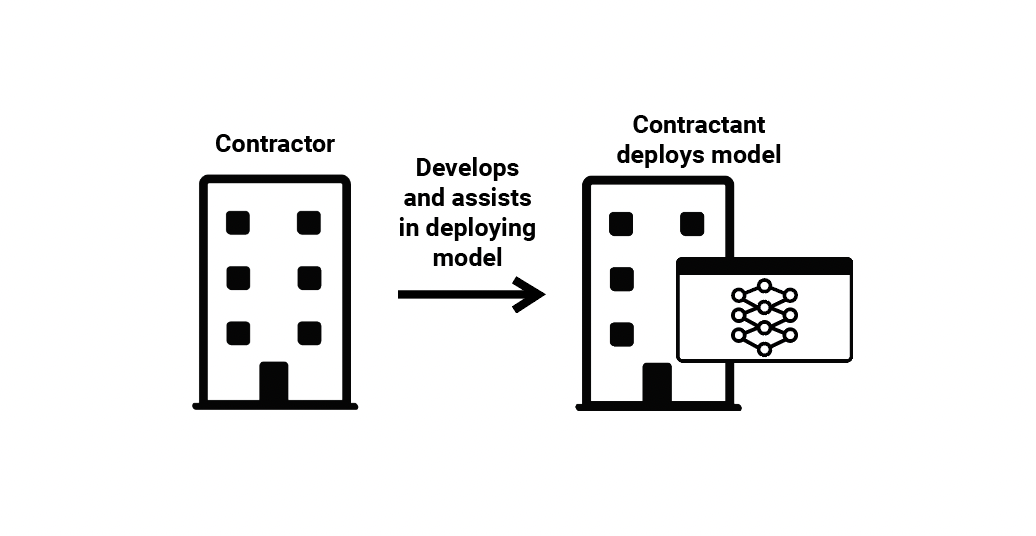
(2) ML Model Contracting—A company that develops a bespoke model as a contractor for a client, but does not itself use that model or sell it more broadly. A contractor who develops customized ML models for financial fraud detection that are directly integrated into a bank’s software is one such example. The contractant (the bank, in this example), deploys the model, and may maintain it itself, or pay the contractor for continued technical support, such as the maintenance and updating of the model.
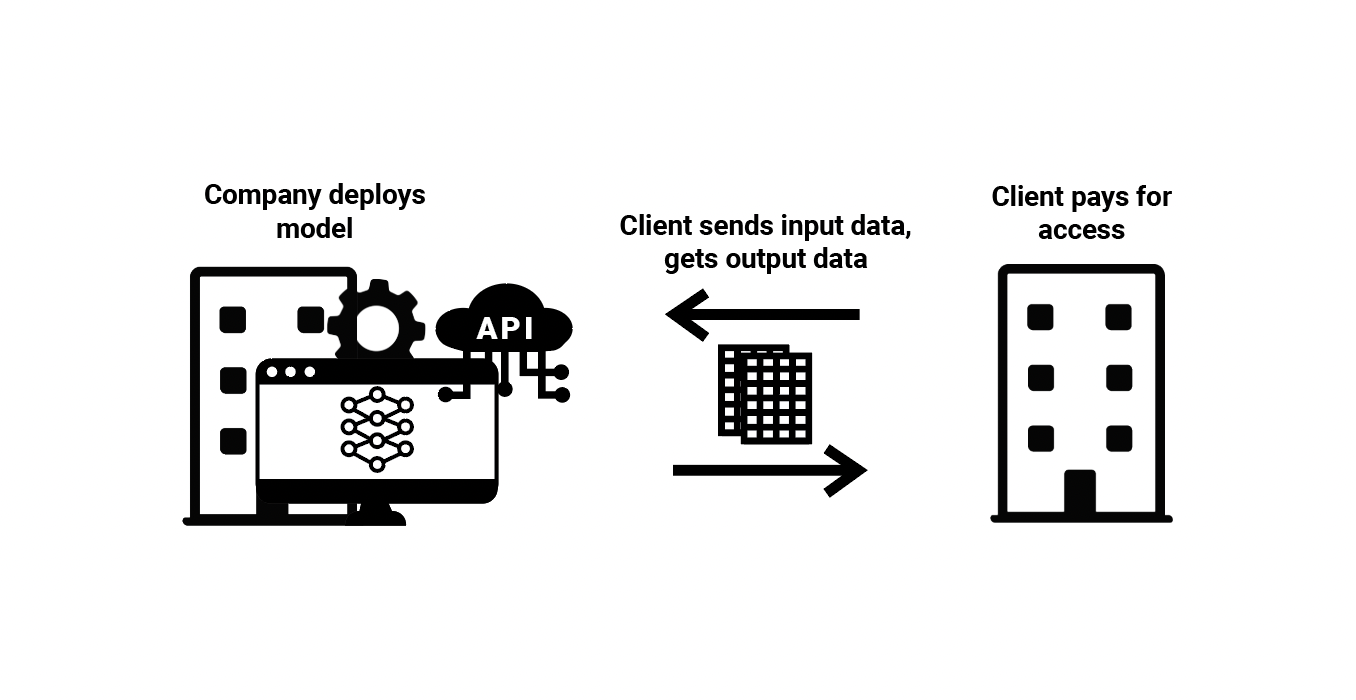
(3) Restricted ML Model Access—A company writes the code and fully trains ML models within a branded application or an application programming interface (API), and then sells access to that application. The company is enabling access to an ML model, but only through closed-source software or an API, preventing any changes to the model. Clients can only submit input data to the ML model and receive outputs back. A company that charges for use of an ML model for image generation based on text prompts, submitted over API, is an example of this ML value chain.
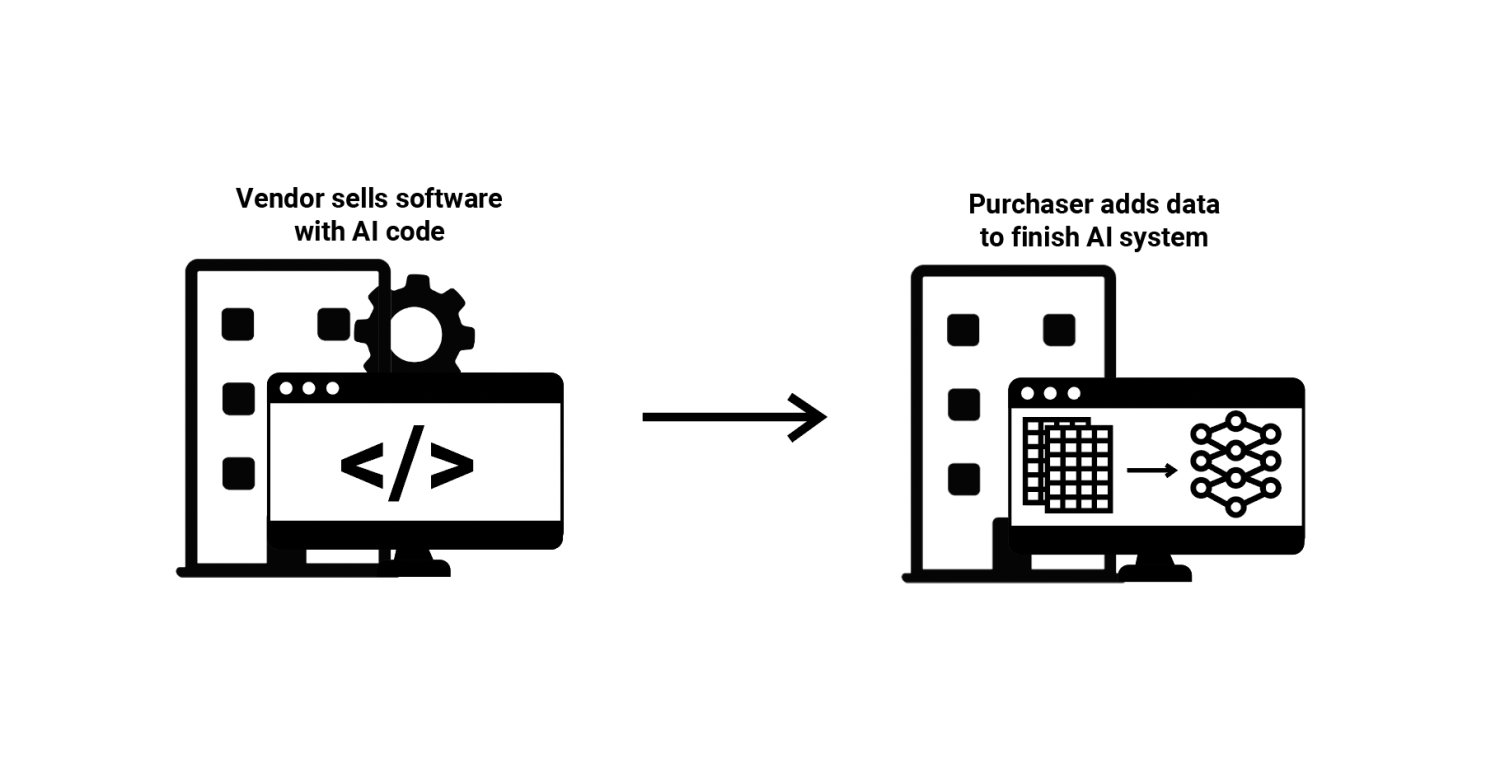
(4) Software with ML Code—A vendor builds software which includes code for training a specific application of an ML model, but the vendor does not provide the data itself or any trained ML models. In this situation, the vendor develops software that includes a process for a client to enter training data of a pre-specified format, which the software can then use to automatically train an ML model. The client purchases the software, adds this training data and further input data, which triggers the automatic ML model creation and then returns new results. At times, the vendor may also provide technical assistance to its clients during this process.
Vendors who sell commercial software used for setting college tuition in the United States employ this approach. The vendor develops the software, including code for training and deploying an ML model, however the vendor never sees the data from individual colleges. The colleges add the data themselves after purchasing the software, and the software automatically trains ML models and presents the results.
(5) Online Machine Learning—A company develops an ML model, as part of a commercial software or product, that can update its models as it receives data from users during its normal operation. Users only provide new data through the process of using the model or the product that contains it, rather than systemically adding new datasets (as will be the case in the sixth type of ML value chain). Typically in online machine learning, the task that the model is performing stays the same (unlike model integration, as we will see) and the changes to the model’s learned patterns and predictions are relatively minor (unlike model fine-tuning, as we will see).
The voice recognition models in Amazon’s Alexa, which adapts to new data from specific human voices, is an example, as are some AI robotic arms which can continue to collect data and update while they are in use.
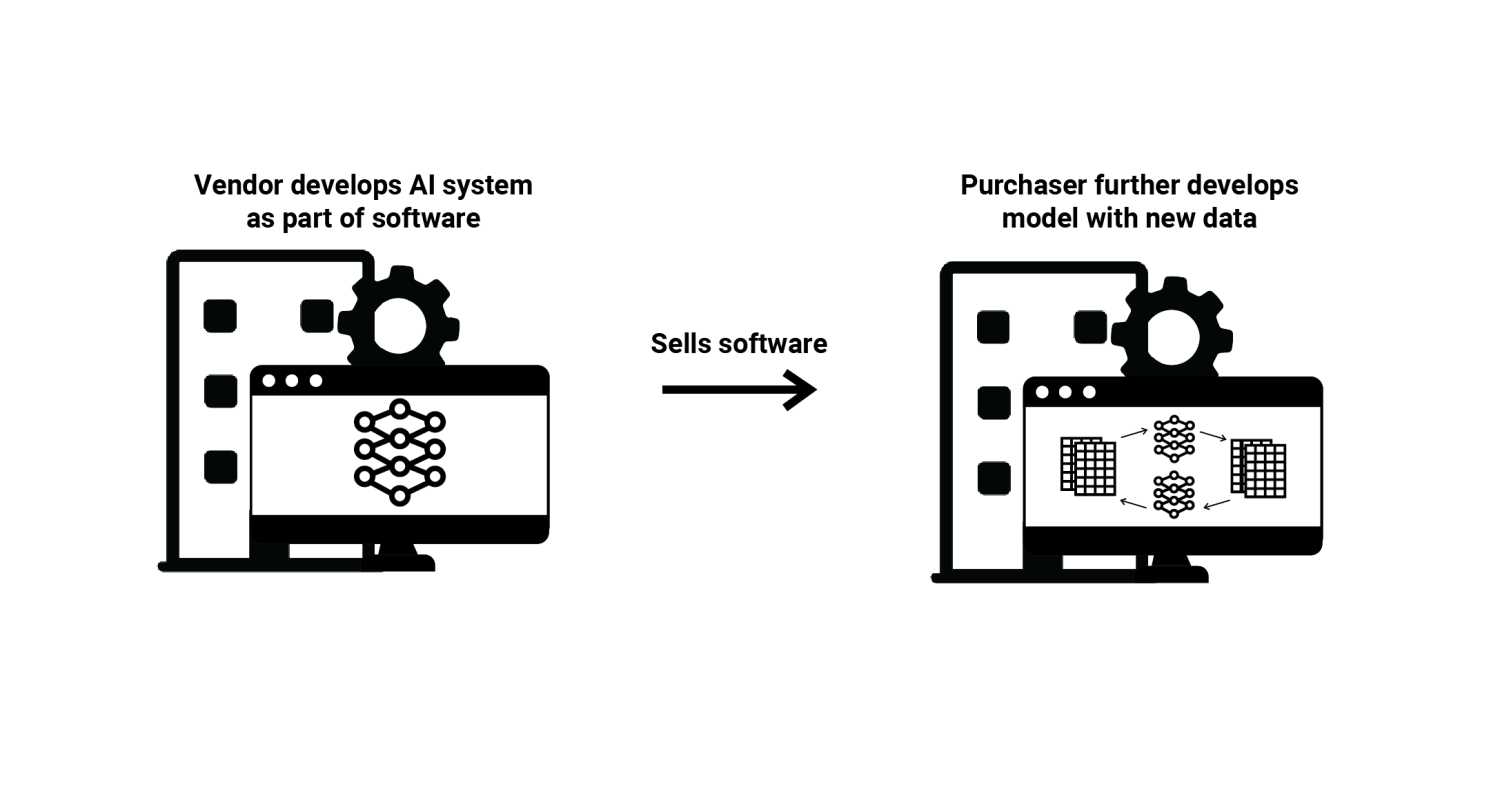
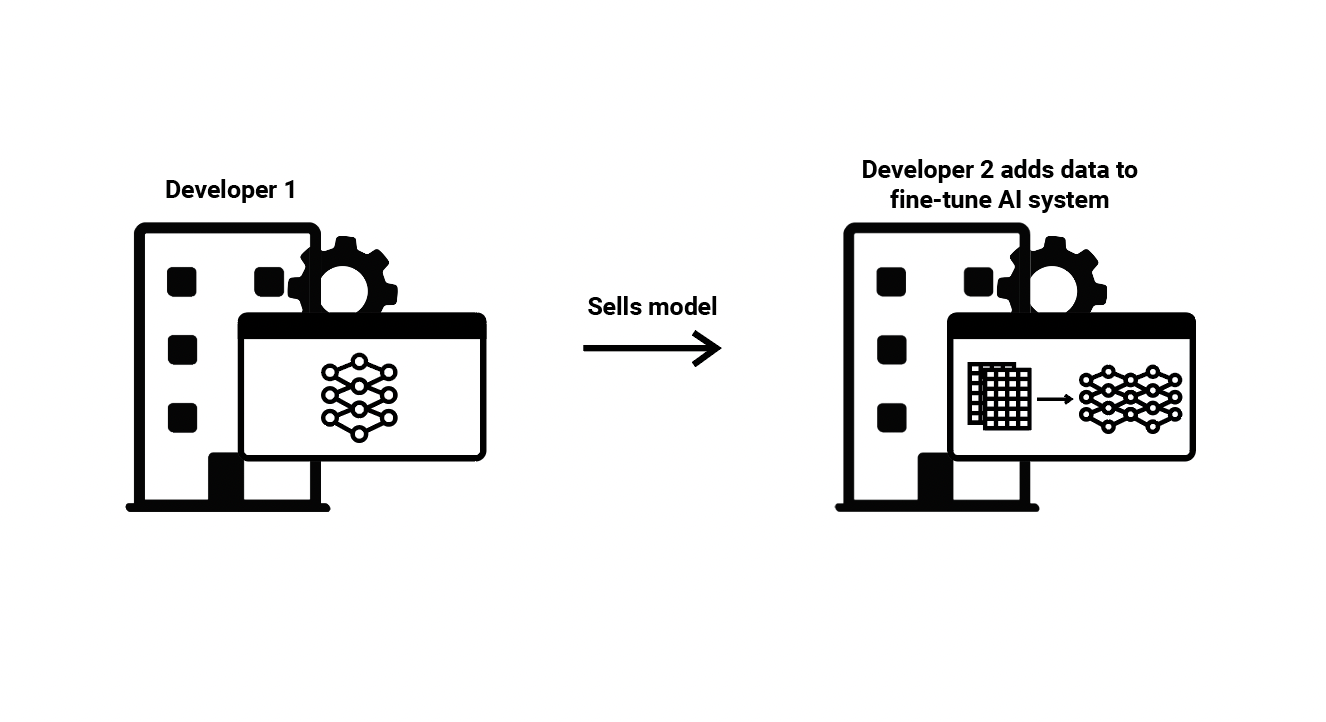
(6) Model Fine-tuning—One developer trains an ML model and then sells it to another developer in such a way that the second developer can continue to train and develop that model. This second developer then fine-tunes the model, meaning it adds additional training datasets to improve the function of the ML model or adapt it to more specific circumstances or tasks. This is distinct from approaches 3, 4, and 5, in that the second developer owns and has direct access to the ML model, and is thus free to manipulate it however they choose. Typically, the data set used to train the first ML model is larger and more general, while the dataset used in fine-tuning is smaller and more specific. A general question-answering chatbot trained by a first developer, then fine-tuned on the specific domain knowledge relevant to a second developer (e.g., to help customers navigate their specific website), is an example of this ML value chain.
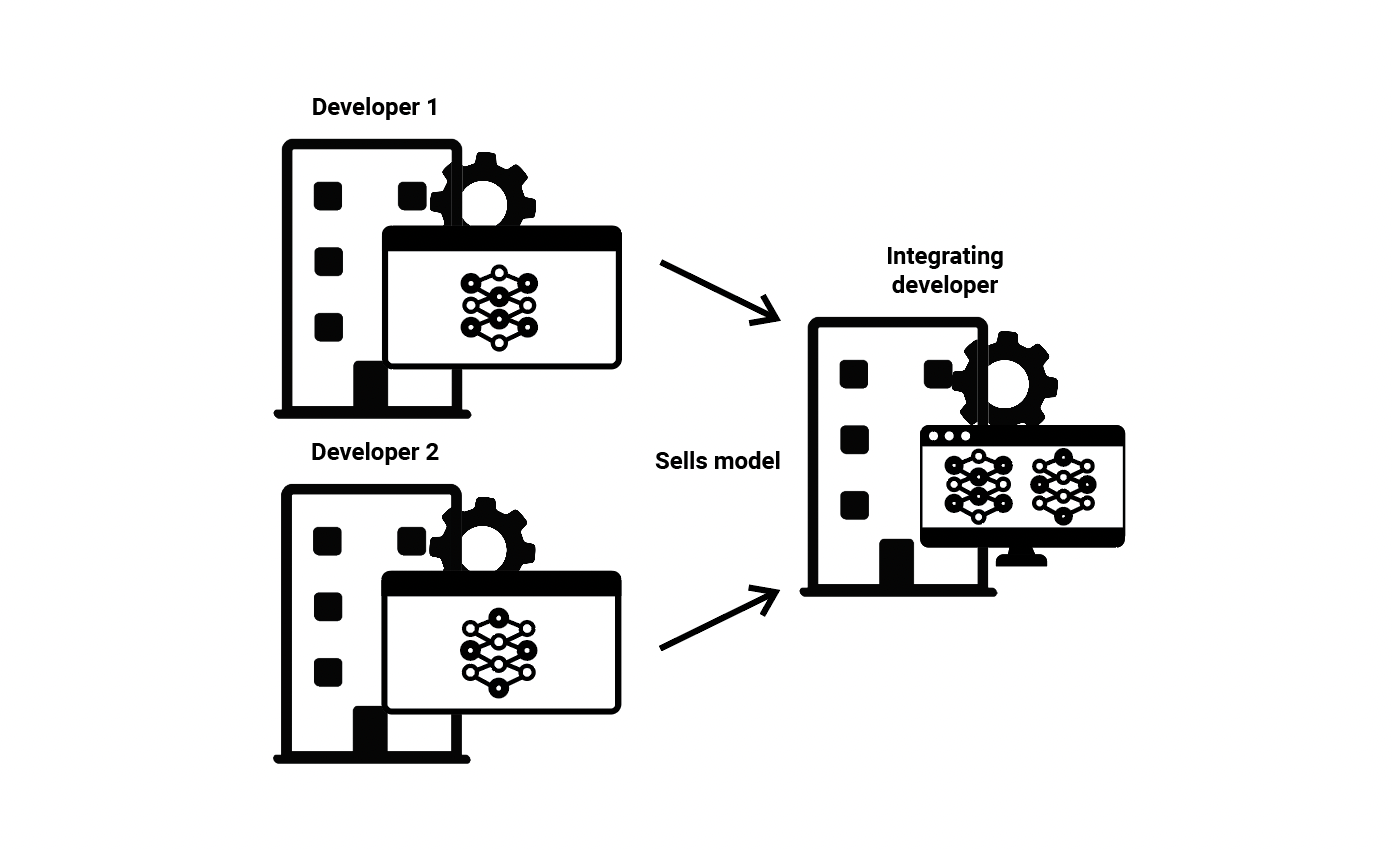
(7) Model Integration—A developer may take several pre-existing ML models and integrate them together into software. In this scenario, there may be many developers. For instance, a company may combine ML models for computer vision, audio analysis, and natural language processing, all from different developers into a single piece of software. Alternatively, integration may consist of combining several ML models to improve their collective function on one specific task, known as ensembling. Model integration may include several of the scenarios discussed above, particularly scenario 2 and scenario 6. Commercial proctoring software that monitors students (with different models analyzing video, audio, text, key entry, etc) as they take an assessment is an example of this approach to the ML value chain.
Divided ML value chains create additional risks
This categorization of real-world ML value chains sheds light on several important policy challenges. By spreading the ML model development process across several organizations, some implementations of the ML value chain create elevated risks of harm. In these approaches, the company that is using the ML system to make decisions or assist in making decisions may not completely understand, or even completely control, the ML model. This is especially true with both restricted ML model access and software with ML code.
In the case of restricted ML model access, users have nearly no insight into the ML model. Users are forced to trust the developing company’s claims and documentation, because they can do almost nothing to evaluate or test the model, other than by sending inputs in and receiving outputs back. While the company that developed the model will better understand its function, it will have little insight into how specifically their clients are using the outcomes from the model. While this may not matter much for generating artistic images, this does warrant hesitancy for using this approach for more substantive applications.
Similarly, in the case of software with ML Code, neither the software developer nor the client that buys the software can fully understand the model or is able to closely scrutinize its determinations. The software developer rarely has access or insight into the underlying data and will never even see the model that results from running the code on that data. As for the client who buys the software, they are typically unable to view or change the code that creates and runs the ML model. This is a severe limitation on how the client can interact with the model—preventing them from making adjustments that might alleviate problems or running analyses that better explain the model’s function. This means neither company has the ability to shape and ensure the model’s appropriate function, creating even more risk than the case of restricted ML model access. Companies should demonstrate extreme reticence in this approach to ML development, and regulators should look more closely at businesses that employ this approach to the ML value chain.
When the process of developing an ML model is split across several organizations, legislators and regulators will have to decide who bears responsibility for the ML model’s function.
Using any ML value chain that creates meaningfully divisions in key aspects of model development, as the two mentioned here do, for risky or impactful decisions is quite dangerous and should generally be avoided. While model fine-tuning and model integration also separate stages of model development, they do so by sharing the model object, which far better enables comprehensive testing and evaluation by the downstream developers. Generally speaking, this is preferable, as it allows more careful and considered use of the ML models by the entity most directly responsible for its determinations and resulting outcomes.
Diversity in the ML value chain creates regulatory complexity
Beyond creating a higher likelihood of harms, some approaches to the ML value chain complicate regulatory oversight and make contractual language more important. When the process of developing an ML model is split across several organizations, legislators and regulators will have to decide who bears responsibility for the ML model’s function.
One clear takeaway from the growing number of approaches to the ML value chain is that contractual language about ML models will become more common and more important over time.
Essentially there are two options for governments—one is to ignore this nuance, and place legal requirements on the last organization in the ML value chain, then allow this entity to shift those legal requirements to other entities using contracts. For example, a company that is relying on a contractor for ML models that determine creditworthiness might try to contractual guarantee from that contractor that the ML models meet relevant legal requirements. One clear takeaway from the growing number of approaches to the ML value chain is that contractual language about ML models will become more common and more important over time.
As a second option, the government can try to define the actors in the value chain, then individually place requirements on them based on their perceived ability to meet them. Presently, the EU is grappling with these issues as it debates and finalizes the Artificial Intelligence Act, trying a combination of both approaches. For instance, it is generally safe to assume that the entity closest to the end-user should bear responsibility for disclosure, that is, informing the user they are interacting with an ML model. This makes sense since this entity will almost always control the environment in which the ML model is deployed, enabling them to implement this transparency.
However, other ML qualities can be more challenging. If legislators wanted to require a certain level of data quality, how can they do so when a final model has been first developed by one company and then fine-tuned by another? Some explainability methods needs to be written into the code that creates an ML model, but can really only be interpreted well within the context of the data—so how do regulators encourage explainability when these are separated, as is the case for software with AI code? These questions are not easily answered.
Existing restrictions on how regulatory agencies can cause issues. For instance, the Equal Employment Opportunity Commission (EEOC) has some authority to investigate companies which hire employees using ML models, but they cannot directly investigate the vendors who sell the software to those employers. Even though there is a general consensus that the vendors are a significant part, if not the key part, of bias in algorithmic hiring, the EEOC cannot act directly on them.
The ML value chain will continue to evolve
This policy brief is intended to put forward an early accounting of emerging approaches to the ML value chain, but it is not complete. It does not comprehensively account for data collection and aggregation, which is clearly part of the algorithmic development process, nor does it consider businesses that provide ancillary services, such as model evaluation, operations, or compliance services, which are all growing cottage markets. Even the distinctions between the categories are imperfect—some ML models offered over API can now be fine-tuned, enabling some user changes, and blurring the line between restricted model access and model fine-tuning. These categories may become even more muddled in the future.
Still, documenting these diverse approaches to the ML value chain is informative. Consulting this list can provide a useful sanity check when considering an ML regulation—does this regulatory approach conform well to these different approaches? Does it preference some over others, and if so, is that advantageous? Lastly, this typology of the ML value chain illustrates one challenge of writing broad and comprehensive laws on ML, much less all of algorithms. For governments still making this choice, the diversity of approaches to the ML value chain might be a further argument for sectorally-specific algorithmic regulation rather than a generalized comprehensive approach.
Related Content



Author

The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).


