The empirical literature suggests that tacit knowledge—skills and intuitions gained through experience and practice—is crucial for the success of human interventions. The fact that the current model of generative AI—essentially, a large predictive system calibrated with past documented data—prevents it from capturing and building on this knowledge should ease concerns over full labor substitution, inform how we rethink education and training, and pave the way for a future of collaboration.
The knowledge transfer paradox
Knowledge could be broadly defined as the understanding, awareness, or familiarity gained through experience, education, or learning, comprising explicit knowledge (factual, information-based, documented, and easily communicated through texts, datasets, or the spoken word) and tacit knowledge (performative, experiential skills, and intuitions gained through practice, and not easily transferred).
AI is redefining our approach to knowledge in ways that are often misunderstood. The knowledge that can be easily transferred is also the one that AI most readily substitutes. However, perhaps paradoxically, this explicit knowledge accounts for only a part, sometimes a minor one, of the ultimate impact of human interventions, enhanced by skills that an experienced practitioner knows, but finds difficult to communicate.
While the incidence of this tacit knowledge is, by definition, hard to quantify, there are ways in which we can assess its relative importance–for example, as the large unexplained part of impact evaluations of public policy.
Why is the impact of labor policies so difficult to identify?
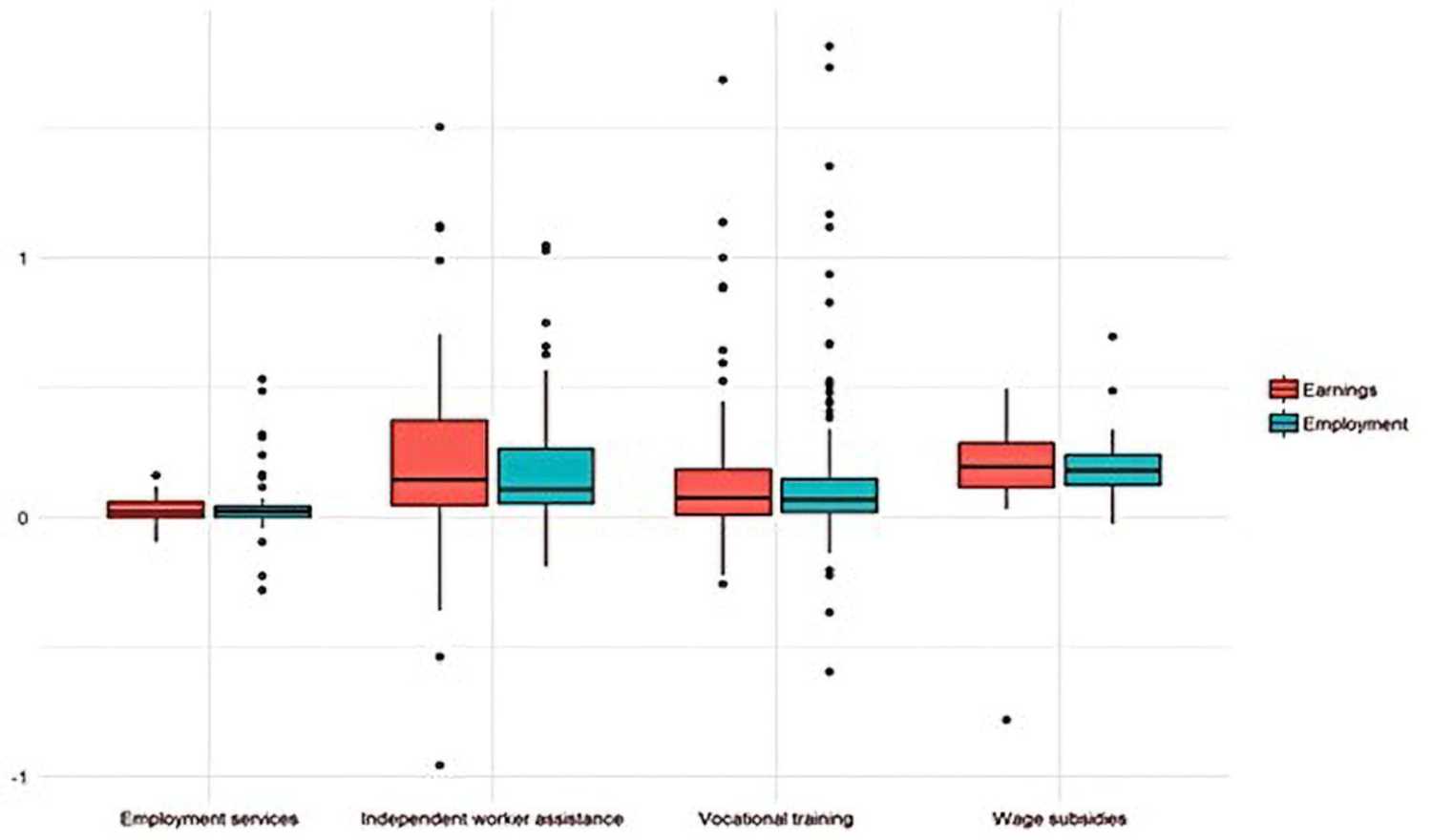
Prompted by the mixed results in previous meta-analyses, we reviewed 102 randomized controlled trials (RCT) of Active Labor Market Policies (AMLP) implemented in recent years.1 Because each intervention typically involves more than one policy, our sample comprised a total of 668 estimated impacts grouped into four AMLP types: (1) employment intermediation services; (2) support for independent workers/micro entrepreneurs; (3) vocational training; and (4) wage subsidies.
The figure below shows a box chart with the distribution of these impacts according to each type: As can be seen, they are statistically insignificant on average—and extremely diverse.
Figure 1. Distribution of estimated impacts of four types of ALMPs
Why is the same intervention effective in one context and a failure in another one?
First, the obvious: ALMPs are implemented in different ways and contexts, and target diverse demographic groups, with varying effectiveness: There is no “optimal design.” Developing a complete design space requires a set of standardized variables to characterize at least five fundamental dimensions: 1) type (e.g., training or wage subsidies); 2) specific components (hard or soft skills, mentoring, monetary stimulus); 3) implementation (duration, public-private cooperation); 4) average cost per participant (often overlooked in impact evaluations); and 5) context (e.g., macroeconomic stance) and target population (demographics).
Statistically significant design variables reported in the paper (for the sub-sample of vocational training interventions) relate to context (impact is positively associated with growth and negatively associated with unemployment); focus (targeting a specific activity improves results); incentives (monetary inducements to participants help); mentoring (individualized follow-up helps); and duration (longer programs yield stronger outcomes). Controlling for the incidence of these (and other) variables on policy impact explains about 30% of the dispersion of the results in the figure–fine for academic publishing, but somewhat troubling for policymaking.
But what about the other 70%: Is it due to measurement error and missing variables, or is it capturing something else?
Written on the body
Paraphrasing Kahneman and Tversky’s distinction, we could think of a system 1 and a system 2 of knowledge. The latter can be conveyed in data and documents, learned through seminars, data sets, and yes, meta-analyses. The former, more experiential, is “embedded” in the practices and memories of the experts that went through these experiences and cannot be regurgitated and communicated in an unexpensive, user-friendly AI-powered platform. The empirical literature suggests that this knowledge– hard to find in meta-analyses and LLM searches–is crucial to the success and impact of human interventions.
The replacement of human labor may take longer than a purely technological perspective might indicate. Non-technological barriers to producer and user adoption go from the demand for original cultural products to commercial responsibility in the absence of appropriate regulation to input restrictions (e.g., users begin to limit—or charge for—their precious data) to the perceived risks associated with the personal information we offer, and the decisions we delegate to a program (leaving us vulnerable to, say, hackers).
Tacit knowledge, which currently can only be transferred in the field by experts themselves, introduces an additional barrier: For it to be learned, shared, and even used by AI, it must be extracted and expressed verbally—in other words, made explicit. Only then could it be added to the body of knowledge upon which AI analyzes and ultimately determines the best response to a practical question.
The algorithm itself agrees:
To learn from tacit knowledge, I, as a language model, do not have direct experiences nor can I observe the world in the same way a person would. My learning is based on analyzing patterns and structures in large amounts of textual data that include descriptions of experiences, case studies, practical examples, and discussions on specific topics. This means that, while I can help you understand and reflect on concepts related to tacit knowledge, I lack the capacity to acquire or apply it in the same way a person would through practice and direct experience.
ChatGPT dixit.
Why do we care?
Perhaps, in the future, we will discover a way to tokenize the intuition, value judgment, and discernment born of practical experience, so they can be added to the training kit for LLMs. Until then, this person-based expertise will require the presence of people in a complementary–and productivity enhancing– way. This distinction has at least two implications for policy.
The first one points to a sobering case of the Turing trap, whereby technology replaces expensive quality human work with a cost-efficient automated substitute of lesser quality. Indeed, to the extent that we start delegating this hit-and-miss, hands-on practice to the algorithm, we run the risk of depriving ourselves of the very experiences on which humans build hard-to-document know how, leading to a more basic, ultimately inferior result–a case of a negative externality that calls for policies to create incentives for human-centered technology in a very specific sense; one that is complementary to human expertise.
The second one directly questions the core of traditional, content-intensive education and training: It stresses the need to shift from information-based studying–where AI cannot be beat–to an action-intensive, expertise-through-practice approach to create a synergy between human labor and AI–including the non-trivial challenge of learning to work with the algorithm.
To end where we started: AI will not fully replace human-specific knowledge–if we continue to nurture it in ways that unlock the possibilities of collaboration.
Author

Related Content



-
Footnotes
- See “How Effective Are Active Labor Market Policies in Developing Countries? A Critical Review of Recent Evidence,” by David McKenzie, The World Bank Research Observer, Volume 32, Issue 2, and “What Works for Active Labor Market Policies?”, by Eduardo Levy-Yeyati, Martín Montané, Luca Sartorio, and Alfonso Gauna, forthcoming Economia.
The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).



Commentary
Why gen AI can’t fully replace us (for now)
December 18, 2024