Conversations around data science typically contain a lot of buzzwords and broad generalizations that make it difficult to understand its pertinence to governance and policy. Even when well-articulated, the private sector applications of data science can sound quite alien to public servants. This is understandable, as the problems that Netflix and Google strive to solve are very different than those government agencies, think tanks, and nonprofit service providers are focused on. This does not mean, however, that there is no public sector value in the modern field of data science. With qualifications, data science offers a powerful framework to expand our evidence-based understanding of policy choices, as well as directly improve service delivery.
To better understand its importance to public policy, it’s useful to distinguish between two broad (though highly interdependent) trends that define data science. The first is a gradual expansion of the types of data and statistical methods that can be used to glean insights into policy studies, such as predictive analytics, clustering, big data methods, and the analysis of networks, text, and images. The second trend is the emergence of a set of tools and the formalization of standards in the data analysis process. These tools include open-source programming languages, data visualization, cloud computing, reproducible research, as well as data collection and storage infrastructure.
Source: Alex Engler/The University of Chicago
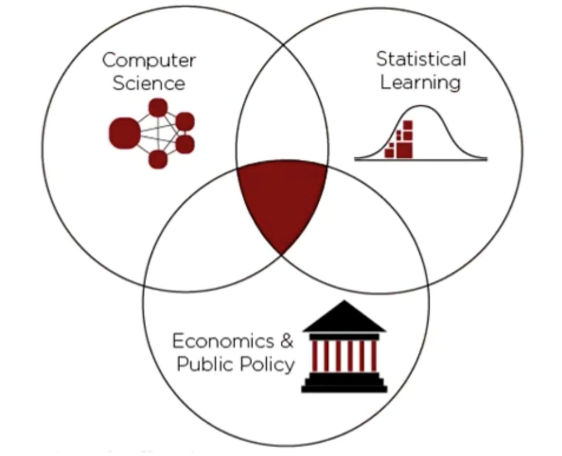
Perhaps not coincidentally, these two trends align reasonably well with the commonly cited data science Venn diagram. In this diagram, data science is defined as the overlap of computer science (the new tools), statistics (the new data and methods), and critically, the pertinent domain knowledge (in our case, economics and public policy). While it is a simplification, it is still a useful and meaningful starting point. Moving beyond this high-level understanding, the goal of this paper is to explain in depth the first trend, illuminating why an expanded view of data and statistics has meaningful repercussions for both policy analysts and consumers of that analysis.
Traditional evidence-building for policy analysis
Using data to learn about public policy is not at all new. The origins of the social sciences using statistical analysis of observational data goes back at least to the 1950s, and experiments started even further back. Microsimulation models, less common but outsized in their influence, emerged as the third pillar of data-driven policy analysis in the 1970s. Beyond descriptive statistics, this trifecta—experiments, observational statistical analysis, and microsimulation—dominated the quantitative analysis of policy for around 40 years. To this day, they constitute the overwhelming majority of empirical knowledge about policy efficacy. While recent years have seen a substantial expansion in the set of pertinent methods (more on that below), it is still critical to have a strong grasp of experiments, observational causal inference, and microsimulation.
Experiments
Since public policy can’t be conducted in a laboratory, experiments are rare in policy studies. Experiments require random assignment, which for policy means a benefit or program is made available randomly to some people and not to others—hardly a politically popular strategy. Many would also say it is ethically questionable to do this, though randomized experiments have taken firm root in medicine, sacrificing fairness in the short term for progress in the long term. Regardless of the political and ethical barriers, they do happen. Experiments are most often supported by nonprofits or created by an accident of governance, and can produce relatively rigorous results, compared to the other methods discussed here.
Perhaps the most famous experiment in modern public policy is that of the Oregon Medicaid expansion. When Oregon moved to expand access to Medicaid in 2008 (before the Affordable Care Act), the state quickly realized that it could not afford to cover all the individuals eligible under the loosened criteria. Opting to randomly select which residents would be able to receive benefits, Oregon officials created the perfect circumstances for researchers to compare recipients of Medicaid with non-recipients who were otherwise very similar. Professors Katherine Baicker and Amy Finkelstein led the research efforts, resulting in extensive evidence that Medicaid improved some health outcomes and prevented catastrophic medical expenses, while also increasing health-care utilization and costs. Signaling a growing interest in this approach, the recent Nobel Prize in Economics recognized three scholars who have taken experiments (sometimes call randomized control trials, or RCTs) into the developing world to examine how to best tackle global poverty.
Statistical analysis of observational data
Due to the financial and political difficulties that experiments present, they remain rare, and much more research is based on the statistical analysis of observational data. Observational data refers to information collected without the presence of an explicit experiment—it comes from surveys, government administrative data, nonprofit service delivery, and other sources. Usually by obtaining and combining several datasets, researchers look for various opportunities to examine the causal effects of policy changes with statistical methods. These statistical methods, broadly called causal inference statistics (or quasi-experiments), take advantage of differences within populations, or policy changes over time and geography to estimate how effective a service or intervention is.
Individually, the strength of the evidence from a single study is limited. (This is true in any field, and it suggests prudence when changing your beliefs based on results from one study.) However, since observational data is far easier to gather and analyze than experimental data, it is possible to find many opportunities to re-examine the same policy questions. Eventually, it’s possible to examine many papers on the same subject, called a meta-analysis. Meta-analysis of observational studies have convincingly argued that increased school spending improves student outcomes, gun access leads to higher risk of suicide and homicide, and that taxes on sugary beverages are associated with lower demand for those beverages.
Although at times difficult to interpret, this slow accumulation of many observational analyses by different research groups often becomes the most informative and trustworthy source of information about potential policy changes.
Microsimulation
Although microsimulation is a lesser-known type of modeling, it remains a critical one. The news is frequently covered in estimates from microsimulation methods, such as how effective taxes would change under the Tax Cuts and Jobs Act and how many people would lose health insurance under the curtailing of the Affordable Care Act. Even a substantial part of the (in)famous Congressional Budget Office scoring of the cost of federal legislation employs microsimulation.
The Urban Institute-Brookings Institution Tax Policy Center model is perhaps the easiest to understand intuitively. The model starts with a sample of anonymized administrative data from the Internal Revenue Service, which contains lots of information about taxpayers that is specific to each person. (This puts the “micro” in microsimulation.) The model itself then does the same thing as online tax preparation software: It runs through the rules of the tax code and calculates how much this person should be paying in taxes. However, the model contains many different knobs that can be turned and switches that can be flicked, each one changing something about the way the tax code works. By altering some of these inputs, the model creates a simulation, that is, an alternative possible outcome from the real world of tax policy.
These models are highly complex, and usually take years to build. They also require a lot of information about how a set of public policies are currently affecting a population, so the data typically comes from government administration records. However, once they are built, they offer a quick and flexible lens into potential policy changes. In reality, the behavioral consequences—how people and firms react to new policy—are large enough that few experts are ever really convinced that estimates from these models are precisely correct. That said, microsimulation methods can ground policy discussions to reasonable predictions, make assumptions explicit, and give a reasonable sense of what complex and interacting policy changes might do. Compared to letting pundits invent numbers out of thin air, microsimulation offer a dramatically more rigorous approach to estimating policy outcomes.
The expanded methods of data science for policy analysis
Nothing discussed above falls outside the field of data science. These approaches all use data, programming, and statistics to infer meaningful conclusions about the world. Still, the term “data science” has some value, as it connotes a broader set of methods and data types than is traditional to the field of policy analysis. While many of these methods have existed for a long time, the proliferation of new and diverse data sources means this expanded toolkit should be more widely understood and applied by policy analysts. Many of the methods detailed below fall into the field of machine learning, but in this case, that terminology complicates the issue without adding much clarity.
Predictive analytics
There is a growing recognition that many government and nonprofit services can be improved with predictive analytics. In Chicago, predictive models are used to reduce the exposure of young children to lead paint, which has extensive and permanent health consequences. Before this effort, and still in most places across the United States, exposed lead paint is typically only discovered after children fall ill.
The Chicago model uses historical inspection data to find correlations between exposed lead paint and other information (like the age of the buildings, when they were last renovated, if they have been vacant, as well as demographic data). This model can then be used to evaluate the level of risk of lead paint in homes that are going to accommodate newborn children. Using those predictions, the Chicago Department of Public Health can more strategically prioritize lead paint inspections, saving many children from hazardous exposure.
This is a generalizable approach for service providers who have a valuable intervention, limited resources, and uncertainty in where their investments would be most beneficial. As another example, the Center for Data Insights at MDRC—a nonprofit, nonpartisan education and social policy research organization—is exploring how to use prediction modeling to better allocate employment services to former inmates. (Disclosure: I am a data science consultant on this project.) If there is trustworthy historical data and an opportunity to affect who gets an intervention, predictive analytics can be highly beneficial by getting services delivered to those who need it most.
Clustering
In public policy, subgroups of a larger population can be very important. Some students score highly on tests, while other score poorly. Some people earn a lot of money from their jobs, while others earn very little. However, although it is tempting to think of groups as separated along a single variable, like the examples above, this is infrequently the case. Some people may earn little money from their jobs, but are in fact in graduate school, have highly educated parents with a strong social support system, suggesting that their income potential is quite high. In some cases, they may be more similar to people earning lots of money than those who earn little but do not have those other supports.
Clustering methods allow for the discovery of these underlying groups across many variables that might otherwise remain hidden or avoid our qualitative intuition. The Pew Research Center has demonstrated this by using clustering methods to examine our assumptions about the political spectrum. Pew researchers applied clustering methods to a survey with 23 questions about political opinions. They discovered that the traditional liberal-moderate-conservative spectrum does not effectively compass the many dimensions of political views that Americans hold. Instead, they argued for seven distinct political subgroups. As just one difference, this more nuanced political analysis notes two groups of conservatives: one more socially conservative, but also critical of Wall-Street; and another more socially moderate, pro-immigration, but also pro-Wall Street.
This is closer to how the world really works—subgroups are complex and nothing is unidimensional. It’s imperative to consider how many variables may be interacting to define the most meaningful differences in whatever populations are being analyzed.
Big data
Sometimes, though certainly not always, simply having more data enables better or different policy analysis. Over the past 12 years, a joint academic initiative at MIT Sloan and Harvard Business School has been using online prices to measure macroeconomic indicators. By scraping data from the internet, the Billion Prices Project has collected the prices of 15 million items from over a thousand retailers. This massive dataset has enabled them to create measures of inflation in 20 countries, updated on a daily basis. For the sake of comparison, the Bureau of Labor Statistics’ (BLS) Consumer Price Index is monthly. Although there are many challenges to this new approach, it’s worth keeping in mind that the traditional process used by the BLS (government employees surveying or physically examining prices) is far more expensive, complicated by its own problems (e.g., growing survey non-response), and painstakingly slow.
While big data can offer new insights, there are important statistical differences when analyzing big data. Most notably, it is generally harder to get data that accurately represents the whole of a population (like a country or a state). Cloud computing and modern software may easily enable analyzing multi-billion row datasets, but that makes it no easier to know who the data is relevant to. Phone records can illuminate strategies to improve traffic patterns, but does it overlook people without mobile phones? Credit card transactions can reveal lifestyle differences across socio-economic groups, but what could be missing without seeing cash transactions and cash-only consumers? This remains a large problem for effectively using big data that is not originally meant for social science (sometimes called “found data”). As a result, it’s a priority to continue the development of methods that can adjust these datasets to be representative and accurate, especially since this new data can offer so much.
Text analysis
Modern text analysis, or natural language processing, offers new ways to glean meaningful insights into the huge bodies of writing that societies produce. For example, consider the impressions that a community has of its law enforcement officers. Trust in the legitimacy of a police force can lead to more lawful behavior, as well as community collaboration to solve and reduce crimes. However, community impressions of police can be hard to measure. This is why the Urban Institute turned to Twitter. Researchers at Urban’s Justice Policy Center analyzed the sentiment of 65 million tweets, finding spikes in negative sentiment after violent police-citizen interactions. It’s worth nothing that this analysis is affected by the big data considerations detailed above.
In another instance, my colleagues in Brookings’s Metropolitan Policy Program looked for overlapping patterns in the text of job descriptions and AI patents. This allows them to create a quantitative estimate of how good AI might be at various job tasks, and thereby, how potentially automatable those jobs might be. This approach creates a new way to reason about the effects of automation that is less dependent on the qualitative judgement of experts.
Network analysis
In their book, “Network Propaganda,” three researchers of Harvard’s Berkman-Klein Center created networks of online media sources, like The New York Times and Fox News. They then measured the sources’ relationships to one another with the hyperlinks in their news content, as well as the social media sharing patterns of their audience. Critically, their research has shown how isolated and self-amplifying far-right media sources have become, leading them to grow more extreme and less tethered to the truth. This is the exact type of insight that network analysis can help deliver: Around whom is the network most dependent? Who is on the fringes and sidelines? How are relationships between actors changing?
While the internet and social media has created huge networks of people, any group of things with relationships to one another can be considered a network and analyzed as such. The states have long been considered laboratories of democracy, where experimental policies can be tested and successful ones shared. This also can be conceived of as a network, with states being connected to one another through the diffusion of similar legislation. Recent research of this kind has provided further evidence of California’s status as a leader in policy innovation. This might be unsurprising, but the same research also highlights Kentucky as the most influential state for the diffusion of public policy from the 1960s until California’s emergence in the mid-1990s.
Image analysis
Image data has proliferated in recent years, originating in everything from cell phones, traffic cameras, smart devices, and even constellations of new satellites. In many parts of the word, especially poor countries, it can be very hard to develop an accurate understanding of poverty—but analyzing image data can help. Unsurprisingly, knowing where impoverished people are is vital to targeting services and investments to help improve their socio-economic outcomes. This is why the World Bank has been developing methods to use high-definition satellite data to create geographically specific measures of poverty, especially relevant to the 57 countries with almost no survey data on poverty. Data science methods can look at satellite imagery and recognize cars, identify roofing materials, distinguish between paved and unpaved roads, and measure building height and density. In turn, these new variables can be used to estimate fairly accurate poverty measures that are substantial improvements over outdated (or nonexistent) estimates.
Satellite data has also been used to monitor international conflicts and as evidence of human rights abuses. Other efforts have proposed using social media photos of political protests to measure their size and degree of violence, though this is likely not ready for implementation. Currently, image analysis is largely limited to facial and object recognition; it is not close to genuine understanding of photos. Still, as imagery proliferates and related modeling techniques improve, this data will offer powerful new ways to examine the state of the world.
Why data science matters to public policy and governance
Evaluating data is becoming a core component of government oversight. The actions of private companies are more frequently in databases than file cabinets, and having that digital information obscured from regulators will undermine our societal safeguards. Government agencies should already be acting to evaluate problematic AI-hiring software and seeking to uncover biases in models that determine who gets health interventions. As algorithmic decision-making becomes more common, it will be necessary to have a core of talented civic data scientists to audit their use in regulated industries.
Even for public servants who never write code themselves, it will be critical to have enough data science literacy to meaningfully interpret the proliferation of empirical research. Despite recent setbacks—such as proposed cuts to evidence-building infrastructure in the Trump administration’s budget proposal—evidence-based policymaking is not going anywhere in the long term. There are already 125 federal statistical agencies, and the Foundations of Evidence Based Policymaking Act, passed early last year, expands the footprint and impact of evidence across government programs.
“Even for public servants who never write code themselves, it will be critical to have enough data science literacy to meaningfully interpret the proliferation of empirical research.”
Further, the mindset of a data scientist is tremendously valuable for public servants: It forces people to confront uncertainty, consider counterfactuals, reason about complex patterns, and wonder what information is missing. It makes people skeptical of anecdotes, which, while often emotionally powerful, are not sufficient sources of information on which to build expansive policies. The late and lauded Alice Rivlin knew all this in 1970, when she published “Systemic Thinking for Social Action.” Arguing for more rigor and scientific processes in government decision-making, Rivlin wrote a pithy final line: “Put more simply, to do better, we must have a way of distinguishing better from worse.”
How to encourage data-scientific thinking and evidence-based policies
The tools and data to distinguish better from worse are more available than ever before, and more policymakers must know how to use and interpret them. A continued expansion of evidence-based decision-making relies on many individuals in many different roles, adopting practices that encourage data-scientific thinking. Managers in government agencies can hire analysts with a rigorous understanding of data in addition to a background in policy. They can also work to open up their datasets, contributing to Data.gov and the broader evidence-based infrastructure. Grant-making organizations have a critical role, too. They should be mandating an evaluation budget—at least 5% of a grant—to collect data and see if the programs they are funding actually work. When they fund research, it should require replicable research and open-data practices.
Technology & Information
5 questions policymakers should ask about facial recognition, law enforcement, and algorithmic bias
Rashawn Ray
February 20, 2020
For policy researchers looking to expand their sense of what is possible, keep an eye on the data science blogs at the Urban Institute and the Pew Research Center, which get into the weeds on how they are using emerging tools to build and disseminate new knowledge. And for current policy analysts who want to deepen their skills, they should consider applying to the Computational Social Science Summer Institute, a free two-week intensive to learn data skills in the context of social problems and policy data. Though much of it is not directly relevant to policy, there is a tremendous amount of online content for self-learners, too. I recommend looking into free online courses and learning to program in R. For those interested in a bigger investment, look to the joint data science and public policy graduate programs, like those at Georgetown University, the University of Chicago, and the University of Pennsylvania.
The Brookings Institution is a nonprofit organization devoted to independent research and policy solutions. Its mission is to conduct high-quality, independent research and, based on that research, to provide innovative, practical recommendations for policymakers and the public. The conclusions and recommendations of any Brookings publication are solely those of its author(s), and do not reflect the views of the Institution, its management, or its other scholars.
Google provides general, unrestricted support to the Institution. The findings, interpretations, and conclusions in this report are not influenced by any donation. Brookings recognizes that the value it provides is in its absolute commitment to quality, independence, and impact. Activities supported by its donors reflect this commitment.
The Brookings Institution is committed to quality, independence, and impact. We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).