At the first White House public workshop on Big Data, Latanya Sweeney, a leading privacy researcher at Carnegie Mellon and Harvard who is now the chief technologist for the Federal Trade Commission, was quoted as asking about privacy and big data, “computer science got us into this mess; can computer science get us out of it?”
There is a lot computer science and other technology can do to help consumers in this area. Some examples:
• The same predictive analytics and machine learning used to understand and manage preferences for products or content and improve user experience can be applied to privacy preferences. This would take some of the burden off individuals to manage their privacy preferences actively and enable providers to adjust disclosures and consent for differing contexts that raise different privacy sensitivities. Computer science has done a lot to improve user interfaces and user experience by making them context-sensitive, and the same can be done to improve users’ privacy experience.
• Tagging and tracking privacy metadata would strengthen accountability by making it easier to ensure that use, retention, and sharing of data is consistent with expectations when the data was first provided.
• Developing features and platforms that enable consumers to see what data is collected about them, employ visualizations to increase interpretability of data, and make data about consumers more available to them in ways that will allow consumers to get more of the benefit of data that they themselves generate would provide much more dynamic and meaningful transparency than static privacy policies that few consumers read and only experts can interpret usefully.
In a recent speech to MIT’s industrial partners, I presented examples of research on privacy-protecting technologies. The following table shows the way certain mobile phone applications collect data in ways that differ from what most of us would expect from the nature of the app or the way it is used.
Dashboard showing App’s Privacy Fingerprints in App store
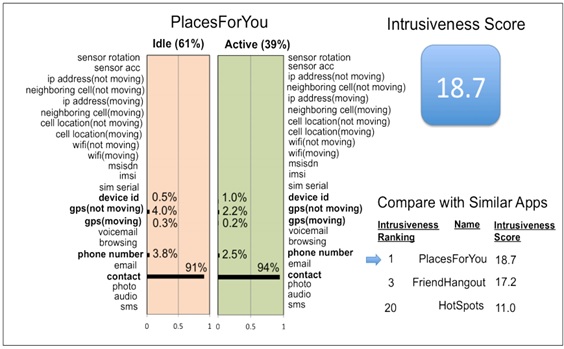
One of the important findings of this research is that consumers make privacy choices based on very intuitive judgments. They typically do not understand what inferences could be drawn from their information in different contexts. Companies know far more about the data than the customers that share it with them. Even if they are aware that not only the GPS devices, but also the accelerometers, microphones, and other sensors on their smartphones are streaming information about them, the inferences that can be — and are — drawn from those data points is the stuff of data science (the new “sexiest job of the 21st Century“) rather than everyday understanding.
That makes for an asymmetrical marketplace. Without a more even bargain, consumers are not able to exercise a real choice to share data in return for free services and convenience. Nor are they able to get much benefit of much of the data they themselves generate. As long as this is the case, there will be something to Jaron Lanier’s vision of the consuming public as data-generating ants in an information ant farm. We need to empower consumers so they can participate in the benefits of a data-driven society in a well-functioning marketplace.
The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).



Commentary
Using Technology to Better Inform Consumers about Privacy Decisions
April 30, 2014