Some 25 years ago, as a young student, I spent three months in the Guinean (Conakry) rainforest to find out if coffee farmers in the region fulfilled the eligibility criteria for joining the “Max Havelaar FairTrade Coffee” Scheme, the first Fairtrade label with a proper certification mark that guarantees that products have been traded under fair conditions. I was particularly interested in documenting the different price levels, from farm gate price and retail price to the export price, to assess what kind of return a “fair priced” coffee could bring to the farmers.
Following my field research, I wanted to compare my findings with the publicly reported official data. So I visited the local national statistical office in Nzérékore, the region’s rain forest capital. After struggling to locate the office, I finally stumbled upon a nearly empty building. With no furniture, computers, or bookshelves in sight, I came across a man sitting behind a desk. On this desk was a book that contained data series, including some on coffee. I was curious to compare data samples and when I showed the officer my findings, he took out a pen, erased his price series, and copied in my own. Needless to say, I was quite perplexed and left the office shortly thereafter.
Why the “who” and “how” of data production matters
Experiencing the desperate state of data collection and, more broadly, National Statistical Offices in many parts of low-income countries, was an eye-opening experience. These sorts of issues were never covered in any course material.
As a junior development economist, you are trained on sampling issues, how to design questionnaires, what secondary sources one should use and general aspects of “data quality.” Data are seen as a “resource” feeding into our econometric modelling—we are looking for “instruments” to deal with endogeneity and are concerned about getting enough “high quality data” as time series to allow more robust analysis. The randomized control trial movement is a particular case in point, with lots of data collection to check whether or not a certain intervention has been successful. These data collection efforts are sometimes undertaken with national partners, sometimes not. The “how” and “who,” as well as the broader governance of data collection, matters for many development outcomes: Leaving them out of our studies risks undermining development efforts.
One illustrative example: The largely donor-driven process in defining indicators and collecting data for the Millennium Development Goals (MDGs) led to the omission of those national statistical systems whose staff questioned the relevancy of the global indicators for national policies, possibly leading to less policy action on the ground. If we take as an example maternal mortality, we find that, in several developing regions, the large majority of data pertaining to MDG 5 is produced by international agencies through modelling, while in the developed countries this data comes from national authorities. To put it differently, in countries with the highest incidence of maternal mortality, the data are largely modeled, while in those where the problem is less severe we can rely on country data. Only recently has a movement around civil registration and vital statistical systems been created to address this important data gap.
Figure 1: MDG date availability, maternal mortality ratio
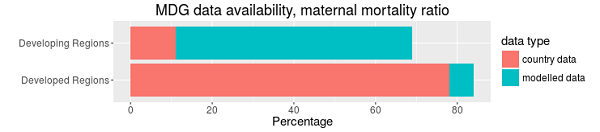
Source: United Nations Statistics Division. (2012). Data Availability by Series and MDG Region as of 2012 from http://mdgs.un.org/unsd/mdg/DataAvailability.aspx
Luckily, the issue of data and need to build national capacities has surged to the foreground of the development debate and is now framed as both a challenge and an opportunity, highlighting the possibilities of new data sources coming from mobile, social or geo-satellite sources (For a more balanced view see the United Nations report “A World that counts” and the PARIS21 “Road Map for a Country-Led Data Revolution”). The replicability movement in economic research has also led to a focus on making research data available to the public. Researchers now have to submit data dissemination plans when applying for data collection grants and initiatives, such as the Harvard Dataverse, which allows for easy documentation and sharing of research data. While this development is welcome, more needs to be done in development economics research.
What can be done?
To start with, there needs to be a shift in how we teach economics and the use of data. Students should be taught how the data they use as secondary source is actually produced, why it is important to understand the different national and international actors, and about different data sources. These range from administrative and census data, to household surveys, as well as data gleaned from alternative sources like satellite imagery and other “big data” sources.
Second, researchers should become data producers not only for their own work, but also to contribute to the data stock within a country. Datasets that are produced through research should be made available to the country in which it was collected, especially in countries where data are lacking. We need to invest in technical solutions that can help with codifying the data, uploading them, and making them interoperable. Quality checks also have to be run.
Third, researchers should team up with national statistical offices in data collection, visualization and dissemination. Strengthening the link between academia and the official statistical office could bring mutual benefits through knowledge transfer, reduced costs, and broader data dissemination.
The data revolution has grabbed the attention and imagination of development economics as a new source for analysis. So let’s use this momentum to address some of the often overlooked issues in how the data we use so often is actually produced.
The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).



Commentary
When development economics undermines development
May 4, 2016