In recent years, breakthrough technologies in artificial intelligence (AI) and the use of satellite imagery made it possible to disrupt the way we collect, process, and analyze data. Facilitated by the intersection of new statistical techniques and the availability of (big) data, it is now possible to create hypergranular estimates.
National statistical offices (NSOs) could be at the forefront of this change. Conventional tasks of statistical offices, such as the coordination of household surveys and censuses, will remain at the core of their work. However, just like AI can enhance the capabilities of doctors, it also has the potential to make statistical offices better, faster, and eventually cheaper.
Still, many countries struggle to make this happen. In a COVID-19 world marked by constrained financial and statistical capacities, making innovation work for statistical offices is of prime importance to create better lives for all. PARIS21 and World Data Lab have joined forces to support innovation in statistical offices and make them fit for this purpose, including Colombia’s national statistical office. If we enrich existing surveys and censuses with geospatial data, it will be possible to generate very granular and more up-to-date demographic and poverty estimates.
In the case of Colombia, this novel method facilitated a scale-up from existing poverty estimates that contained 1,123 data points to 78,000 data points, which represents a 70-fold increase. This results in much more granular estimates highlighting Colombia’s heterogeneity between and within municipalities (see Figure 1).
Figure 1. Poverty shares (%) Colombia, in 2018
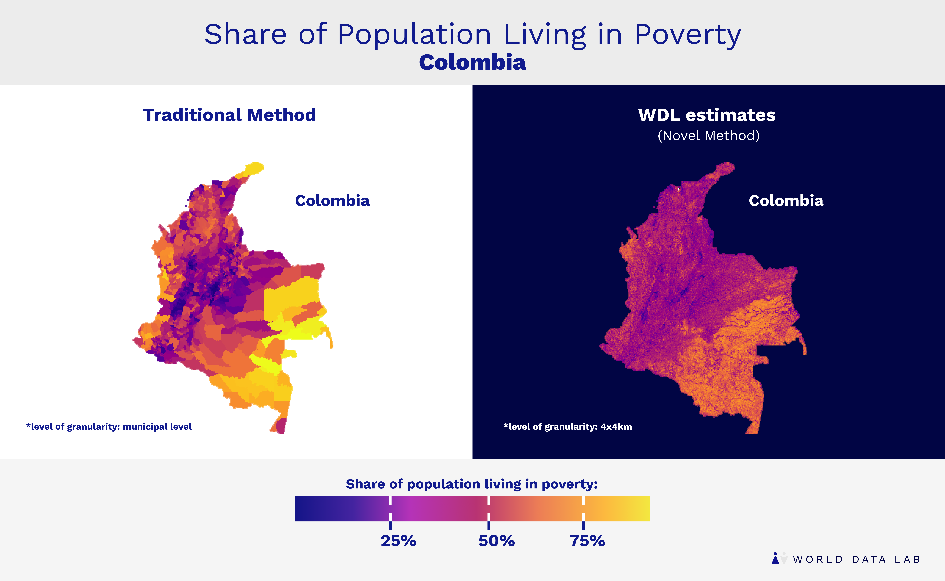
The averages for each municipality still contain big variances as poverty depends on many more factors than geography.
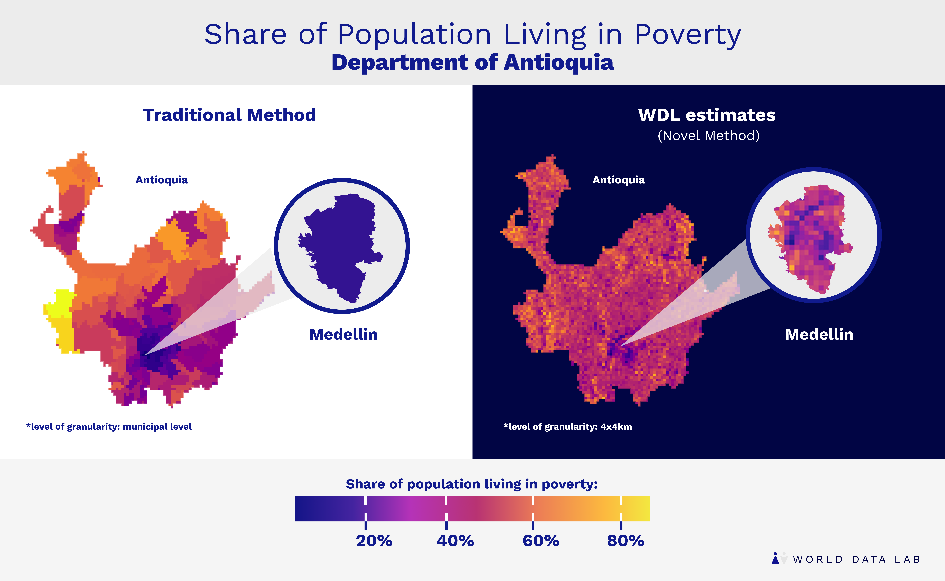
Traditional methods don´t allow for cost-efficient hypergranular estimations but serve as a reference point, due to their ground-truthing capacity. Hence, we have combined existing data with novel AI techniques, to go down to granular estimates of up to 4×4 kilometers. In particular, we have trained an algorithm to connect daytime and nighttime satellite images. In a next step, we have used this algorithm to predict poverty rates based on daytime satellite imagery. Since these remotely sensed data are available on a very granular level, this has allowed us to significantly increase the granularity of the data on poverty. Finally, we have combined these predictions with information from the latest census to ensure their reliability. This combination of traditional and novel techniques has allowed us to capture the variance in poverty rates across and within communities all over the country. Applying these techniques to poverty shares sheds light on the differences in poverty rates in Colombia, even within municipalities. Take the department of Antioquia with its capital Medellín, the second largest city in Colombia. In Figure 2, the detected variance, which is as high as 48 percent, becomes visible by comparing the existing data with the hypergranular estimates.
This reveals the capabilities of combining conventional poverty analysis methods with novel AI techniques and the potential to get more granular in the future.
Figure 2. Poverty shares (%) in Antioquia, in 2018
We further used satellite imagery to predict population density on the city-block level, by using a machine-learning technique called Random Forest. This approach builds on a large number of individual classifications or regression trees, each of them aimed at providing the best possible prediction. Averaging over the predictions of all individual trees eventually leads to the final prediction of the Random Forest. This technique has allowed us to distribute input data on the municipality level to a granularity of a 100×100 meter area. Breaking down each municipality into even smaller fractions reveals immense deviations from the average. Let us take the district of Bogotá D.C. as an example. The census data suggest an average population density of 46 persons living in a range of 100×100 meters. However, our methods reveal a more heterogeneous distribution, notably between rural and urban regions, ranging from one to 999 people per 100×100 meters. This instance shows how we can drastically improve the granularity of existing data by integrating state-of-the-art methods and novel data types into our analysis.
Figure 3. Population density in Cundinamarca in 2018
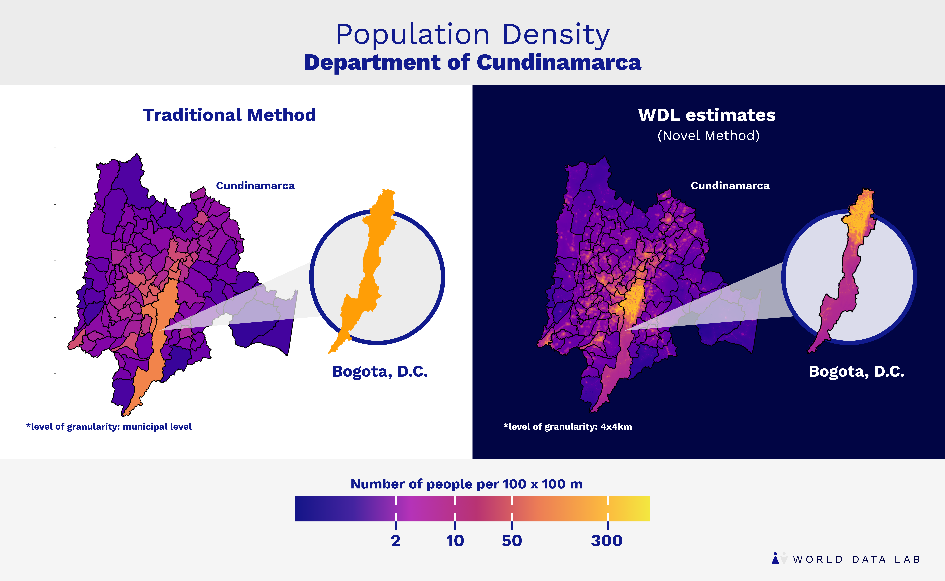
Previous examples show how valuable this kind of engagement is in a country like Colombia, where 42.5 percent of the population lives in monetary poverty, with great disparities between and even within municipalities (as shown in Figure 2). The granularity obtained from the use of novel machine-learning methods, as developed in this exercise, allows public entities to formulate and implement policies that focus on the most vulnerable and strive to leave no one behind—even more as these policies can be addressed to the most suitable areas, with the highest impact. The outcomes of this collaboration have proven to be essential for the decisionmaking processes associated with the recovery agendas to overcome the difficulties caused by the COVID-19 pandemic.
In conclusion, innovation in statistical methods and AI technology could be a facilitator for NSOs to become the main provider for data-based decisionmaking. The opportunity to create hypergranular and quality data depends on the investment of resources in AI techniques and novel scientific approaches. The future demand for, and the technical improvement of, real-time data and forecasts can resolve the prevalent perfectionism fallacy in NSOs. Consequently, contributing to technical innovation and partnering up with providers of cutting-edge enterprises will accelerate the transformation process. If this opportunity window is used properly, we can pave the way for statistical offices to enter the 21st century.
Related Content


Authors




The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).



Commentary
Can national statistical offices shape the data revolution?
September 3, 2021